We owe a lot to the cloud data warehouses, but their era of hegemony is coming to an end.
Over the last 10 years, companies like Snowflake modernized a whole industry, which previously relied on a closed and proprietary ecosystem of self-managed deployments (powered by Oracle, Teradata, and the like). They enabled organizations to move petabytes of critical workloads to the cloud, opening up these datasets to a wider range of integrations, collaboration, and applications – democratizing access to data and dramatically increasing its value.
Over time, businesses began to examine their data stores more closely, considering both the nature of the information contained within and the potential utility that could be derived. With organizational data now more readily available, development teams transitioned from static batched reporting to constructing interactive applications—both for internal use and external distribution.
However, here is where they started running into challenges. Because cloud data warehouses are designed for offline reporting (just now running on cloud infrastructure), their architecture and pricing models are not optimized to serve as the backend for interactive, data-driven applications. So organizations end up with poor performance (10s of seconds to minutes response time, instead of sub-second and milliseconds), skyrocketing costs (often 3-5x compared to alternatives), and low query concurrency (unfit for externally-facing applications).
As a result, organizations have turned to the real-time analytics databases optimized to power data-intensive applications. The adoption and operationalization of these real-time analytics databases over time has led to a new architectural pattern that we term the real-time data warehouse. Below, we describe why a traditional data warehouse is not designed for the needs of real-time analytical applications, and how a real-time data warehouse addresses these challenges as well as leads to an architectural shift to “unbundle the cloud data warehouse.”
Traditional data warehouse: one size does not fit all
Traditional data warehousing has been around for many years. It was designed to unify internal business reporting in the era where offline and batch processing were the norm, and typically relied on:
- heavy batch ETL jobs for moving data from source systems
- massive joins of large tables to unify disparate datasets for centralized querying
- static “views” or “marts” for different teams to consume specific datasets
Once this data was available in the cloud, however, it was then tempting to blur the boundaries of the use cases beyond data warehousing
The rise of the cloud data warehouse, led by platforms like Snowflake, BigQuery, and Redshift, has helped to modernize data warehousing by providing scalability, convenience, and, most importantly, flexibility and openness to a very important class of data workloads. Once this data was available in the cloud, however, it was then tempting to blur the boundaries of the use cases beyond data warehousing, presenting cloud data warehouses as a "one-size fits all" approach for all use cases ranging from user-facing analytics to server side-transformations, dashboarding, observability, machine learning, and so on. This has led to recurrent performance challenges, a degraded user experience, and significant runaway costs, calling for a need to reevaluate the data architecture.
Interactive, data-driven apps are eating the world
It is tempting for an established industry to dismiss a trend toward building new types of applications as niche. If you ask a traditional data warehouse architect, they may tell you that “batch data ingestion and reporting” is fine, but nothing could be further from the truth.
Daily use of interactive, data-driven productivity applications is now a requirement for marketing, sales, engineering, operations, and virtually all other professionals. These applications are driven by analyzing vast amounts of data in a highly interactive way. For example, if you are a marketer, you need to understand who visits your website, who is looking at your social media posts, and how your ads are consumed – all in real-time. If you are a financial analyst, you are expected to make multiple mid-day and end-of-day decisions promptly in a fast-changing market. If you are a DevOps engineer working on a 24/7 SaaS service, you are responsible for increasingly high demands around availability of your applications - 99.999% uptime means only 5 minutes of downtime per year!
As a result, whole new industries have emerged, whose needs cannot be solved by a traditional data warehouse and instead require a real-time data warehouse.
- Marketing analytics provide visibility into marketing campaigns from many channels - web, social, ad activity, summarize this information, allow marketers to run interactive queries and reports, and proactively surface outliers in the sea of data - e.g. fast-growing regions, sub-markets, or sectors, and suggest ways to optimize marketing spend.
- Sales analytics show activity in the sales region, such as lead flow by source, usage of the product in free / trial use, sales cycle activity, post-sale consumption, account health, and churn, summarize this data, and proactively raise important opportunity or risk factors for the sales professionals to act on - key prospects and at-risk customers.
- E-commerce and retail analytics cover the retail life cycle - from merchandising and stocking, to sale activity, to fulfillment, enable over time tracking and interactive querying of this data, and proactively suggest ways to optimize logistics of the operation.
- Financial analytics track financial instrument activity such as buy, sell, put, call, and allow analysts to quickly pivot on this information based on multiple selection criteria, and suggested actions, including potential future trades and hedges.
- Observability and IoT monitoring ingest structured logs, metrics, and tracing events from SaaS infrastructure or manufacturing floor and devices, cross reference it with metadata like device and user information, and summarize error and latency information overtime, as well as forecasted areas of trouble based on historical data.
Furthermore, many datasets driving the core of a SaaS business will also be used by internal stakeholders to understand their business. Thus, both external and internal users are important to consider.
Internal users are increasingly demanding
Internal users of analytical applications include product, marketing, and business analysts, who have been the primary audience targeted by data warehousing systems. However, these users are no longer willing to settle for a slow time-to-insights experience. To stay competitive in their roles, they need to make data-driven decisions faster, and if internal data platforms do not meet their requirements, they will advocate for adopting a 3rd party tool with fast, interactive performance.
In addition to existing internal use cases, businesses are increasingly staffing internal AI/ML initiatives, and internal data scientists need query access to the same data to develop better ML models and AI-based capabilities. Data scientists also need interactive performance - the speed of queries directly correlates to how fast they can develop new machine learning models or build AI-based capabilities.
Cloud data warehouses are a poor fit for real-time analytics
As users attempt to use cloud data warehouses for real-time analytics, they face challenges because traditional data warehouse architectures and pricing models are not optimized to serve as the backend for interactive, data-driven applications.
Requirements for these applications typically include the ability to:
- Serve queries combining continuously-loading and historical data (up to years)
- Serve queries requiring highly-interactive access patterns, such as complex filters and aggregations, at high concurrency rates
- Achieve query latency sufficient for immersive applications (ideally sub-second)
- Operate on up to terabytes and petabytes of historical data while processing millions of events per second ingest
Instead, with cloud data warehouses, users face:
- Data propagation delay. Internal data engineering teams struggle to serve these increasingly demanding audiences from traditional data warehouses as a result of multi-hour delays caused by data propagation through complex ETL pipelines, reliance on highly-denormalized datasets that demand expensive JOINs and slow down real-time applications, and the sheer financial cost of supporting real-time query performance in the legacy architectures.
- Slow query performance. Users get query performance with response times measured in tens of seconds or even minutes, instead of milliseconds, and when they try to improve it by throwing more compute at the problem, they run into the next concern – cost.
- Skyrocketing costs. It is not uncommon for users of cloud data warehouses to pay 3-5x compared to alternatives, even for sub-par performance, because their pricing is expensive and their architecture requires more system resources for the same workloads.
- Low query concurrency. Query concurrency requirements are much higher than a traditional data warehouse expects – hundreds and thousands of concurrent users running queries with interactivity and latency expectations of millisecond responses, and at disruptively lower costs.
In the end, cloud data warehouses can only serve low-latency, interactive workloads by overcompensating in terms of cost. It is like paying exorbitant amounts of money to continuously modify an old car to race in Formula 1, when the correct and cheaper answer is to use an actual F1 car.
In the end, cloud data warehouses can only serve low-latency, interactive workloads by overcompensating in terms of cost - either by paying a lot more for premium features like materialized views in Snowflake, or throwing more and more compute to churn through queries faster in BigQuery. It is like paying exorbitant amounts of money to continuously modify an old car to race in Formula 1, when the correct and cheaper answer is to use an actual F1 car.
Introducing the real-time data warehouse
A real-time data warehouse is a convergent data platform optimized for running data-intensive interactive applications serving both internal and external audiences.
Today, businesses tape together multiple systems to satisfy evolving requirements around interactive applications without re-thinking the overall architecture of their data systems. Introducing the concept of a real-time data warehouse simplifies data flows and reduces the number of dependencies.
For example, the following architecture is not uncommon for a modern organization dealing with large amounts of analytical data and trying to introduce a component that can handle real-time analytical workloads. This architecture combines the use of a real-time analytical database (to support external applications), but still leverages the traditional data warehouse for other internal use cases.
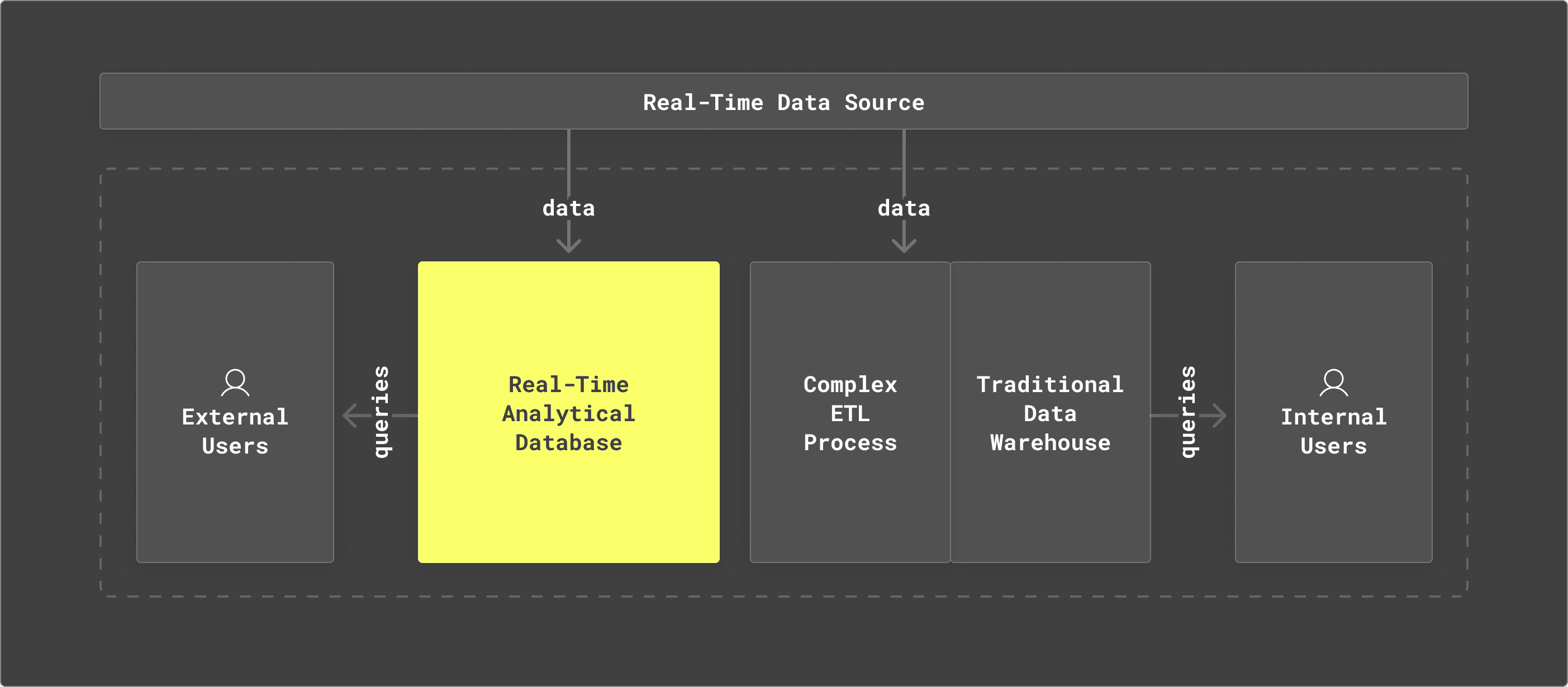
Modern data stack with high reliance on a traditional data warehouse
The real-time data warehouse solves this challenge in a different way: it embraces both external and internal interactive data applications in a unified way and offloads offline reporting (if needed) to a cold archiving system — increasingly commonly an object store, but sometimes also a traditional data warehouse in a decreased capacity.
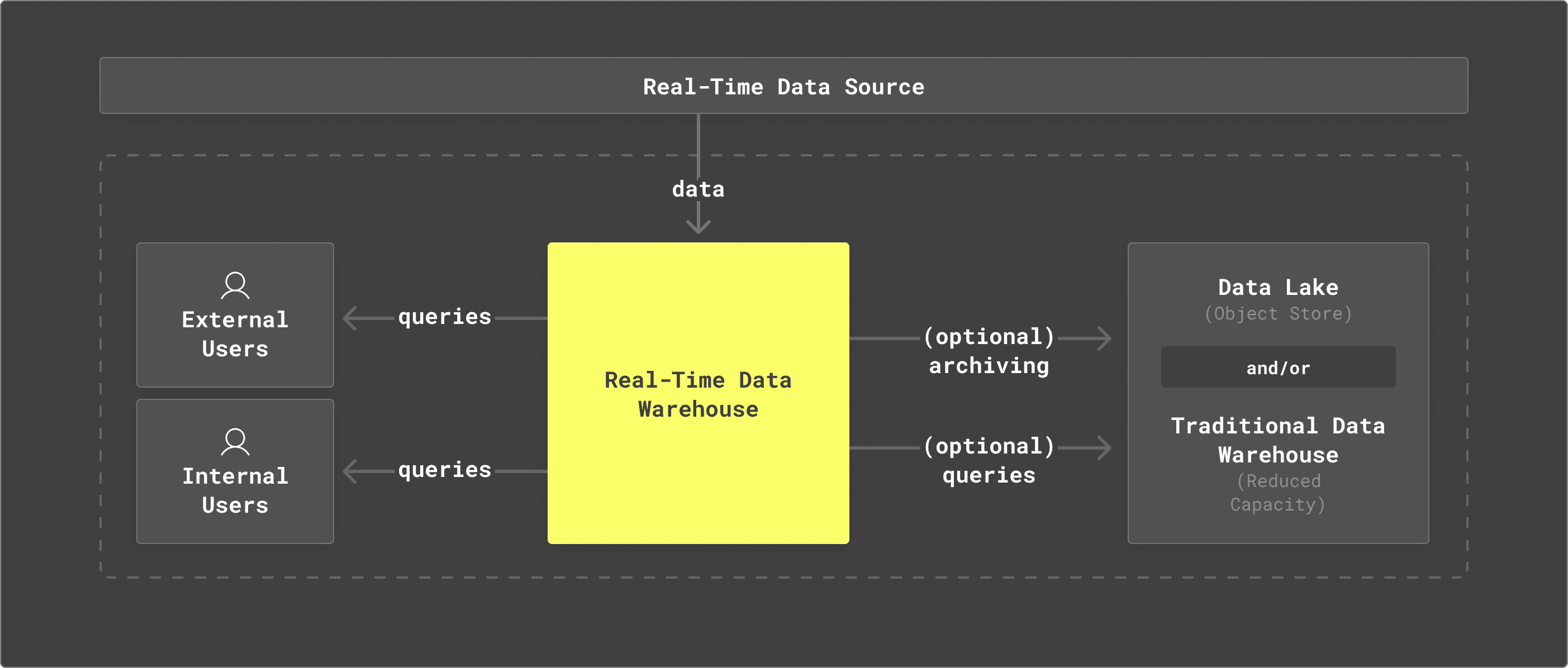
Modern data stack based on real-time data warehouse
The unbundling of the cloud data warehouse
We call the evolution away from a monolithic cloud data warehouse the “unbundling of the cloud data warehouse.” Organizations that go through this transformation carefully examine and identify workloads that are needed for building interactive data-driven applications and move those workloads to a real-time data warehouse.
In the process, they also make the determination whether the rest of the cold data should stay in a traditional data warehouse, or move to a more open architecture based on the concept of a “data lake.” Adopting a data lake has advantages such as cheaper storage and increasingly open standards (Delta Lake, Iceberg, and Hudi on top of Parquet data format). This means that for applications that don’t need real-time performance, multiple teams and applications can have access to the same source of truth, without the need to store data multiple times or keep it in a proprietary system.
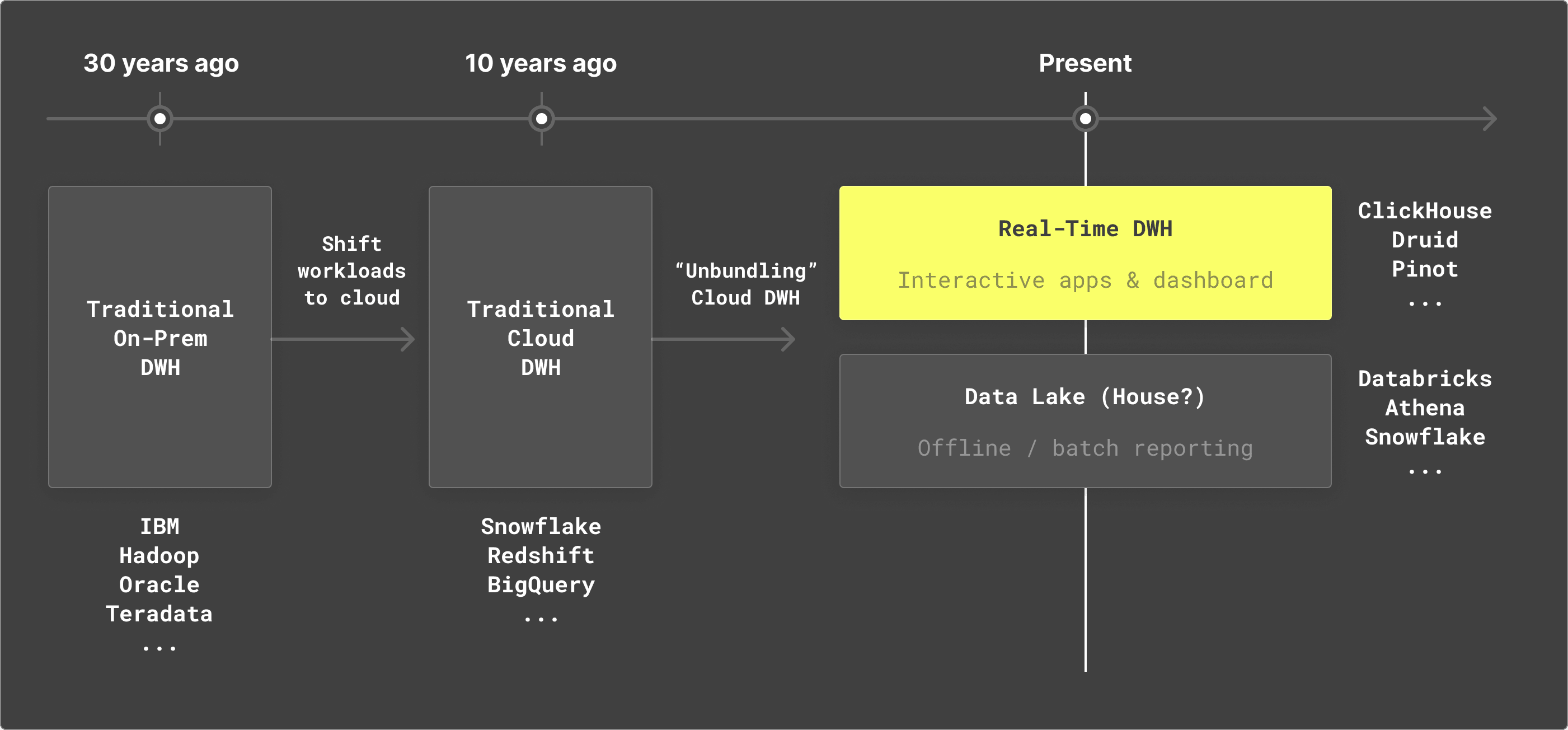
How the data ecosystem has evolved over the past thirty years
This is not the first wave of unbundling in the data ecosystem. We went from mainframes (bundled) to relational databases (unbundled) to traditional data warehouses (bundled) to early cloud providers (unbundled) to cloud data warehouses (bundled). So will this unbundling trend stick?
We predict that most of them will move toward a more vendor-neutral data lake approach over time, and cloud data warehousing vendors will open up their technology stacks to include capabilities to run on top of data lakes directly.
No matter what the answer is, we believe the trend to separate storage and compute across data platforms (with object store serving as the primary data store) is going to play a major role. We see it driving continued adoption of data lakes for warm and cold storage across vendors and technologies. While some organizations will stick with traditional data warehouses for a while due to existing investments, we predict that most of them will move toward a more vendor-neutral data lake approach over time, and cloud data warehousing vendors will open up their technology stacks to include capabilities to run on top of data lakes directly.
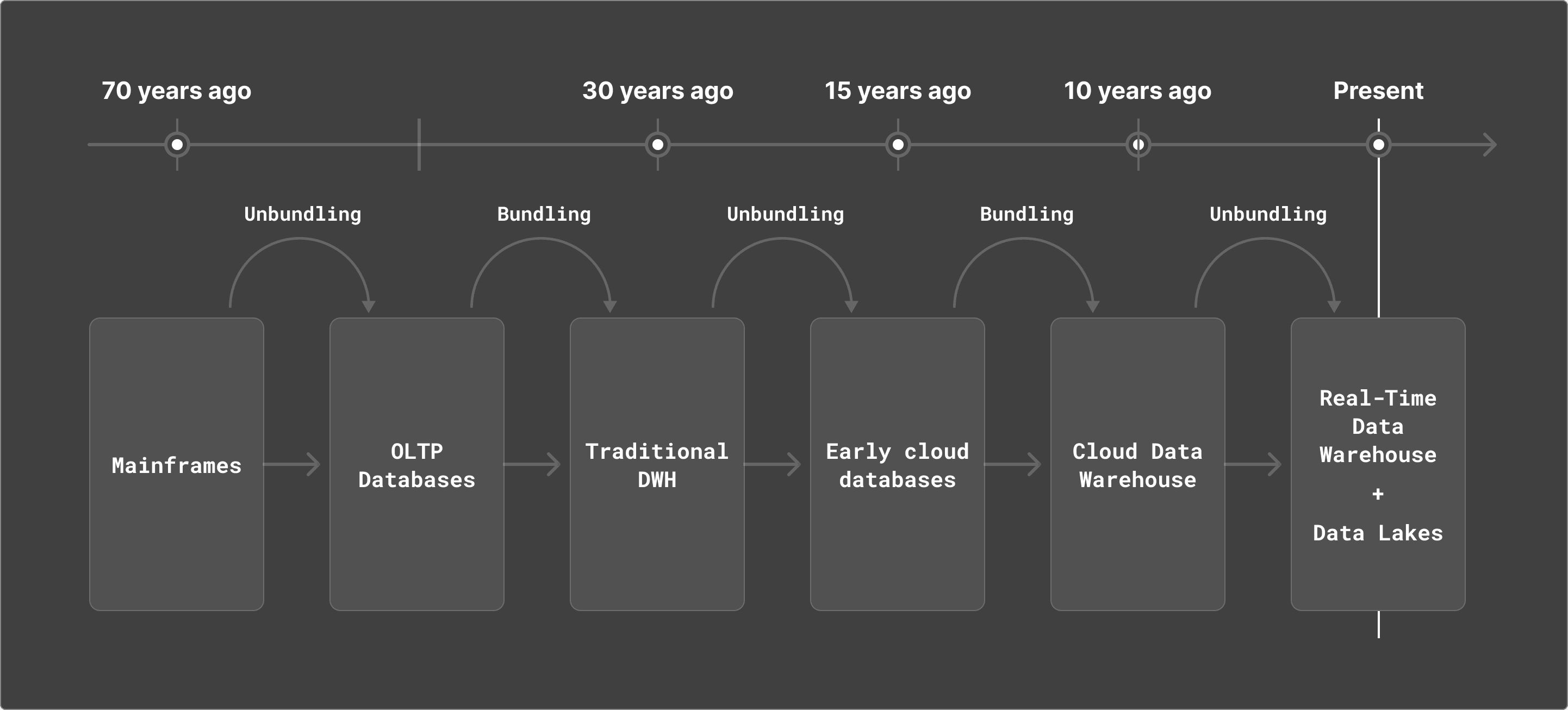
Unbundling / Rebundling Cycle
How to choose the right real-time data warehouse for your use case
To meet both the high demands of interactive data-driven applications and the practicality of reasonable cost at scale, a real-time data warehouse must support:
- Turnkey continuous data loading from real-time data sources, such as Apache Kafka
- Continuously-updating materialized views to make even heavy queries run in seconds
- Millisecond performance of filter and aggregation queries on billions of rows
To ensure utility for internal analysts, the real-time data warehouse must support:
- Integrations with BI tools, such as Apache Superset, Grafana, Looker, Tableau for internal users
- Ability to archive to a data lake on an object store
- Ability to perform ad-hoc queries on data stored in object stores
To meet these requirements, increasingly it is necessary for real-time data warehouses to operate in a separated storage and compute architecture, optimized to the needs of real-time workloads by leveraging the latest capabilities of the object stores. Benefits of this architecture result in independent scaling of compute vs storage, automatic and horizontal scaling of the compute layer, both of which result in better dynamic allocation of resources that improve performance and cost of compute. For large datasets (many terabytes and petabytes), this also results in much more reasonably priced storage costs.
Finally, as a growing number of use cases demand integration of traditional analytics with AI-enhanced analytics, increasingly it is a requirement for an analytical database to power machine learning capabilities like model training and vector search.
ClickHouse as a real-time data warehouse
These were the requirements upon which we built ClickHouse Cloud, and as a result, it outperforms traditional data warehouses by orders of magnitude in real-time applications.
ClickHouse Cloud is based on ClickHouse, currently considered the most popular open source real-time analytical database. Since becoming open sourced in 2016, it has gained wide adoption across use cases and industry verticals.
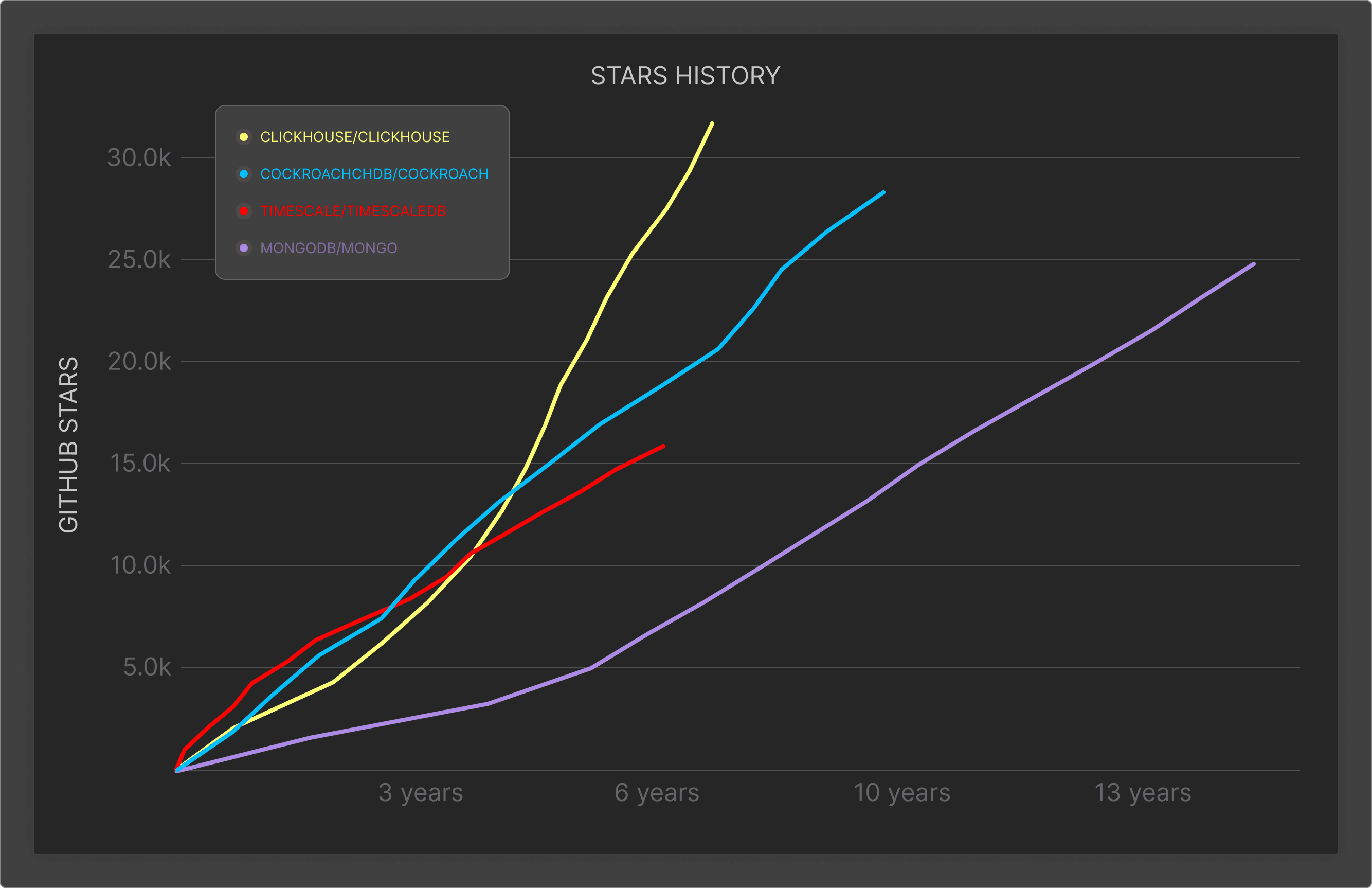
ClickHouse is used as a backend for the most popular SaaS services on the web, across marketing, sales, retail, and e-commerce analytics. It is also a popular backend for observability applications, used both by SaaS providers of observability services and internal teams building custom observability platforms. In all of these use cases, ClickHouse ingests data continuously from real-time data sources like Apache Kafka, and runs highly concurrent analytical query workloads powering customer-facing applications. One of its super-powers leveraged by many users are materialized views, which allow for really flexible in-place data transformation and drastic query speed-up. ClickHouse easily achieves millisecond-level analytical performance on top of billions of rows.
When it comes to internally-facing applications, ClickHouse is increasingly used as an alternative to traditional data warehouses, like Snowflake, Redshift, and BigQuery, because of its broad ecosystem of integrations that make it easy to move data from object stores to ClickHouse as well as run queries from ClickHouse as a query engine directly on top of data stored in object stores in Parquet and many other formats and optionally managed by Iceberg, Delta Lake, and Hudi.
ClickHouse is emerging as a data platform for building the next generation of Gen AI (generative artificial intelligence) applications. With ClickHouse, developers can store training data and vector embeddings in addition to their application data and events, all in a single database, combining AI-based and heuristics-based analytics in one data store.
ClickHouse Cloud expands on these fundamentals. It gives users and administrators a turnkey way to deploy ClickHouse with separation of storage and compute — an architecture that has many benefits including virtually limitless storage and effortless horizontal scaling of compute. In ClickHouse Cloud, this architecture has been optimized to run real-time workloads with low-level optimizations leveraging object store parallelism, sophisticated caching, and prefetching techniques. ClickHouse Cloud comes with built-in tooling for administrators (cluster management, observability, backups) as well as analysts (SQL console, BI tool integration, AI-assisted SQL queries).
Conclusion
The cloud data warehouses accomplished what many considered impossible: shifting huge analytical workloads from proprietary mainframe-like self-managed solutions to the cloud. This evolution ultimately resulted in a close examination of how warehoused data could be used to build increasingly interactive data-driven applications and led to an increasing trend to unbundle the cloud data warehouse, now deployed in a more open and interconnected environment.
As a result of this trend, the real-time data warehouse is evolving as a key architectural component for building data-intensive interactive applications. It is used to power customer-facing applications, as well as enable internal stakeholders to leverage the same datasets for business analytics and data science. The real-time data warehouse serves as the main datastore for analytical datasets powering real-time applications, and is typically combined with data lakes on object storage for long-term archiving and ad-hoc access to the data not requiring real-time performance.
Additional reading
To find out more about how ClickHouse is adopted in these use case, please see:


