For most of the time that I’ve been aware of ClickHouse, my understanding was that it was an analytics database with a traditional client-server architecture, designed to serve a high volume of concurrent queries with low latency.
It’s only in the last few months that I became aware of a couple of tools that have changed my understanding: ClickHouse Local, which lets us run an in-process version of ClickHouse frontend by a CLI, and chDB, an embedded SQL OLAP Engine powered by ClickHouse.
I’ve found myself using a mixture of these tools for the majority of the videos that I’ve been creating for the ClickHouse YouTube channel.
The one most notable exception was a video explaining Materialized Views with help from ClickPy. ClickPy is a ClickHouse service hosted on ClickHouse Cloud that contains data on the downloads of packages from Python’s PyPi package manager. The dataset helps us understand the most downloaded packages over time, grouped by country, installer, version, and a number of other dimensions.
The database also contains metadata about each package, including a project homepage, which is often a GitHub repository. It got me thinking that it would be quite interesting to compare the GitHub metrics (e.g. star count or number of forks) of those libraries against the download numbers.
I asked my colleague Dale whether we could add the GitHub data onto the ClickPy server and he suggested that I first take a look at ClickHouse’s remote and remoteSecure table functions. These functions let you query remote ClickHouse servers on the fly from another ClickHouse client. We can also join the data from a remote query with data in the local ClickHouse, which when used with ClickHouse Local means that we can achieve a kind of hybrid query execution.
I should point out that this isn’t a use case for which ClickHouse is currently optimized, but I thought it would be a fun experiment, so let’s get to it!
Querying GitHub metrics with ClickHouse Local
I wrote a little Python script to download data from the GitHub API for as many of the projects as possible, storing each project in its own JSON file on my machine. For example, below is a subset of the data for the Langchain project:
{
"id": 552661142,
"node_id": "R_kgDOIPDwlg",
"name": "langchain",
"full_name": "langchain-ai/langchain",
...
"topics": [],
"visibility": "public",
"forks": 10190,
"open_issues": 2109,
"watchers": 69585,
"default_branch": "master",
...
"subscribers_count": 606
}
We’re going to explore these files using ClickHouse Local, so let’s launch that on our machine:
./clickhouse local -m
We can run the following query to find the most popular PyPi packages according to GitHub stars:
FROM file('data/*.json', JSONEachRow)
SELECT full_name, stargazers_count AS stars, forks
ORDER BY stargazers_count DESC
LIMIT 10;
┌─full_name────────────────┬──stars─┬─forks─┐
│ huggingface/transformers │ 116073 │ 23147 │
│ langchain-ai/langchain │ 69585 │ 10190 │
│ tiangolo/fastapi │ 65210 │ 5519 │
│ yt-dlp/yt-dlp │ 60914 │ 4994 │
│ keras-team/keras │ 59836 │ 19477 │
│ ansible/ansible │ 59352 │ 23867 │
│ openai/whisper │ 51217 │ 5828 │
│ localstack/localstack │ 50301 │ 3822 │
│ Textualize/rich │ 45582 │ 1686 │
│ psf/black │ 35545 │ 2339 │
└──────────────────────────┴────────┴───────┘
10 rows in set. Elapsed: 0.140 sec. Processed 2.08 thousand rows, 14.97 MB (14.91 thousand rows/s., 107.28 MB/s.)
Peak memory usage: 48.50 KiB.
I suppose it’s not too surprising to see that quite a few of the libraries used in Generative AI applications are much loved on GitHub.
Querying popular PyPi projects on ClickHouse Cloud
Now we need to work out which projects in the ClickPy database have a GitHub repository as their project home page. Let’s first connect to the ClickPy database using the read-only play user:
./clickhouse client -m \
-h clickpy-clickhouse.clickhouse.com \
--user play --secure
And now let’s write a query that finds the most popular PyPi projects that have a GitHub repository. We’ll do this by joining the pypi_downloads and projects tables. We run the following directly on the server:
SELECT name,
replaceOne(home_page, 'https://github.com/', '') AS repository,
sum(count) AS count
FROM pypi.pypi_downloads AS downloads
INNER JOIN (
SELECT name, argMax(home_page, version) AS home_page
FROM pypi.projects
GROUP BY name
) AS projects ON projects.name = downloads.project
WHERE projects.home_page LIKE '%github%'
GROUP BY ALL
ORDER BY count DESC
LIMIT 10;
┌─name───────────────┬─repository─────────────────┬───────count─┐
│ boto3 │ boto/boto3 │ 16031894410 │
│ botocore │ boto/botocore │ 11033306159 │
│ certifi │ certifi/python-certifi │ 8606959885 │
│ s3transfer │ boto/s3transfer │ 8575775398 │
│ python-dateutil │ dateutil/dateutil │ 8144178765
│ charset-normalizer │ Ousret/charset_normalizer │ 5891178066 │
│ jmespath │ jmespath/jmespath.py │ 5405618311 │
│ pyasn1 │ pyasn1/pyasn1 │ 5378303214 │
│ google-api-core │ googleapis/python-api-core │ 5022394699 │
│ importlib-metadata │ python/importlib_metadata │ 4353215364 │
└────────────────────┴────────────────────────────┴─────────────┘
10 rows in set. Elapsed: 0.260 sec. Processed 12.28 million rows, 935.69 MB (47.16 million rows/s., 3.59 GB/s.)
Peak memory usage: 1.02 GiB.
Let’s have a look at a diagram that shows where the different bits of data reside.
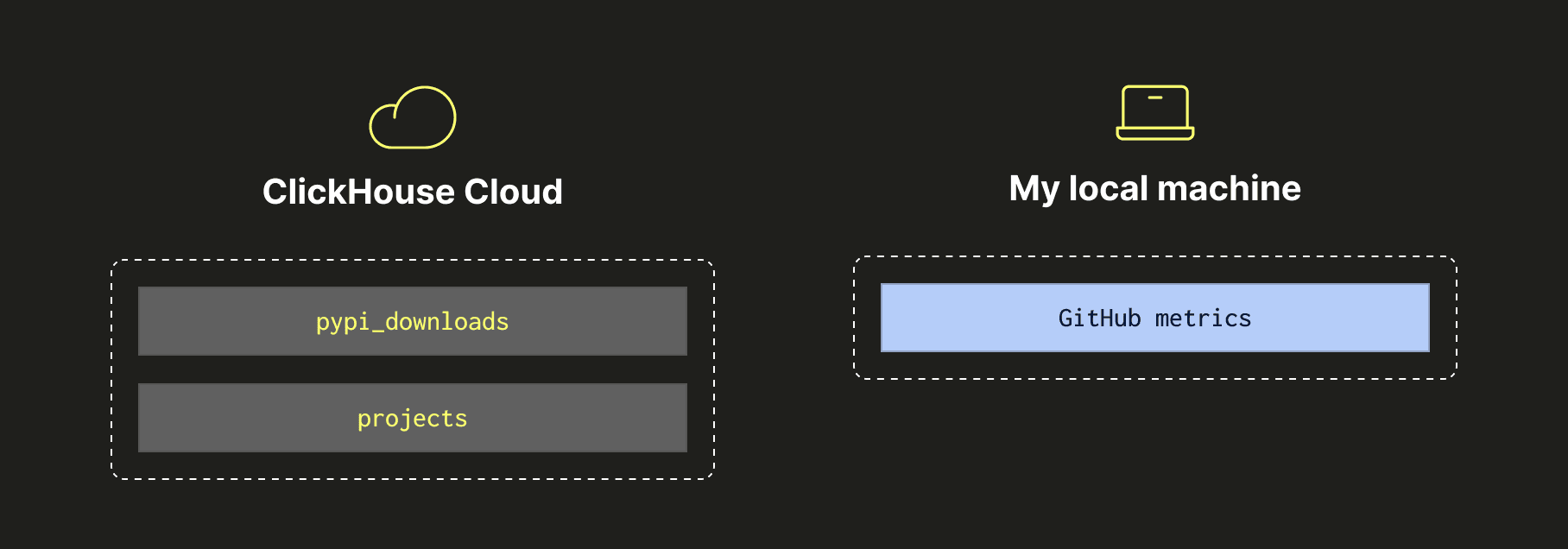
Configuring permissions for remote querying
What I want to do next is combine the query that finds PyPi projects with the one that returns GitHub metrics. The main challenge is that the PyPi data is on Clickhouse Cloud, while the GitHub metrics is on my machine.
I don’t want to pollute the ClickHouse Cloud instance with my GitHub data, so instead I’m going to use the remoteSecure table function to query ClickHouse Cloud from my machine. In order to use this function to join the projects and pypi_downloads tables, we’ll need to create a user that has the following permission:
GRANT CREATE TEMPORARY TABLE, REMOTE ON *.* TO <user>
Once i’ve created a user called _mark_ on the ClickPy server that has this permission, we can return to our ClickHouse Local session and define a password as a parameter:
set param_password = 'my-password';
Querying ClickHouse Cloud from ClickHouse Local
And now we’re going to run a version of the above query, that finds the most popular PyPi projects, using the remoteSecure function.
SELECT name,
replaceOne(home_page, 'https://github.com/', '') AS repository,
sum(count) AS count
FROM remoteSecure(
'clickpy-clickhouse.clickhouse.com',
'pypi.pypi_downloads',
'mark', {password:String}
) AS pypi_downloads
INNER JOIN
(
SELECT name, argMax(home_page, version) AS home_page
FROM remoteSecure(
'clickpy-clickhouse.clickhouse.com',
'pypi.projects',
'mark', {password:String}
)
GROUP BY name
) AS projects ON projects.name = pypi_downloads.project
WHERE projects.home_page LIKE '%github%'
GROUP BY ALL
ORDER BY count DESC
LIMIT 10;
┌─name───────────────┬─repository─────────────────┬───────count─┐
│ boto3 │ boto/boto3 │ 16031894410 │
│ botocore │ boto/botocore │ 11033306159 │
│ certifi │ certifi/python-certifi │ 8606959885 │
│ s3transfer │ boto/s3transfer │ 8575775398 │
│ python-dateutil │ dateutil/dateutil │ 8144178765 │
│ charset-normalizer │ Ousret/charset_normalizer │ 5891178066 │
│ jmespath │ jmespath/jmespath.py │ 5405618311 │
│ pyasn1 │ pyasn1/pyasn1 │ 5378303214 │
│ google-api-core │ googleapis/python-api-core │ 5022394699 │
│ importlib-metadata │ python/importlib_metadata │ 4353215364 │
└────────────────────┴────────────────────────────┴─────────────┘
10 rows in set. Elapsed: 1.703 sec.
As we’d expect, we get the same results as before. This query takes a bit longer to run because, although the JOIN is done on the ClickPy server, we are initializing a new connection to the ClickPy server each time we run the query. We can check that the join is done remotely by prefixing the query with EXPLAIN PLAN, which will return the following:
┌─explain───────────────────────────────────┐
│ ReadFromRemote (Read from remote replica) │
└───────────────────────────────────────────┘
If the JOIN was being done locally, we would see a Join operator in the query plan.
Joining data from ClickHouse Cloud with ClickHouse Local
Next, let’s join this data with the local GitHub dataset:
SELECT
projects.name,
replaceOne(home_page, 'https://github.com/', '') AS repository,
sum(count) AS count,
gh.stargazers_count AS stars
FROM remoteSecure(
'clickpy-clickhouse.clickhouse.com',
'pypi.pypi_downloads',
'mark', {password:String}
) AS pypi_downloads
INNER JOIN
(
SELECT name, argMax(home_page, version) AS home_page
FROM remoteSecure(
'clickpy-clickhouse.clickhouse.com',
'pypi.projects',
'mark', {password:String}
)
GROUP BY name
) AS projects ON projects.name = pypi_downloads.project
INNER JOIN
(
SELECT *
FROM file('data/*.json', JSONEachRow)
) AS gh ON gh.svn_url = projects.home_page
GROUP BY ALL
ORDER BY stars DESC
LIMIT 10;
This results in the following output:
┌─projects.name────────────┬─repository───────────────┬─────count─┬──stars─┐
│ in-transformers │ huggingface/transformers │ 881 │ 116073 │
│ richads-transformers │ huggingface/transformers │ 1323 │ 116073 │
│ transformers-machinify │ huggingface/transformers │ 999 │ 116073 │
│ transformers-phobert │ huggingface/transformers │ 4550 │ 116073 │
│ transformers │ huggingface/transformers │ 302008339 │ 116073 │
│ langchain │ langchain-ai/langchain │ 35657607 │ 69585 │
│ langchain-by-johnsnowlabs│ langchain-ai/langchain │ 565 │ 69585 │
│ langchain-core │ langchain-ai/langchain │ 2440921 │ 69585 │
│ gigachain-core │ langchain-ai/langchain │ 4181 │ 69585 │
│ langchain-community │ langchain-ai/langchain │ 1438159 │ 69585 │
│ gigachain-community │ langchain-ai/langchain │ 1914 │ 69585 │
│ yt-dlp-custom │ yt-dlp/yt-dlp │ 948 │ 60914 │
│ yt-dlp │ yt-dlp/yt-dlp │ 86175495 │ 60914 │
│ keras │ keras-team/keras │ 374424308 │ 59836 │
│ keras-nightly │ keras-team/keras │ 20349029 │ 59836 │
│ symai-whisper │ openai/whisper │ 790 │ 51217 │
│ test10101010101 │ openai/whisper │ 46 │ 51217 │
│ whisper-openai │ openai/whisper │ 11486 │ 51217 │
│ openai-whisper │ openai/whisper │ 2029106 │ 51217 │
│ localstack │ localstack/localstack │ 3998353 │ 50301 │
└──────────────────────────┴──────────────────────────┴───────────┴────────┘
20 rows in set. Elapsed: 3.704 sec. Processed 12.28 million rows, 950.66 MB (3.31 million rows/s., 256.66 MB/s.)
Peak memory usage: 339.80 MiB.
huggingface/transformers, langchain-ai/langchain, and openai/whisper are repeated several times. This is because there are different PyPi projects using the same GitHub repository as their homepage. Some of those look like genuinely different projects, but others seem to be abandoned forks of the main project.
This query takes almost 4 seconds to run because the result of the join of the projects and pypi_downloads tables is being streamed to my ClickHouse Local instance before the join with the GitHub data is done. We can see a diagram showing how this works below:
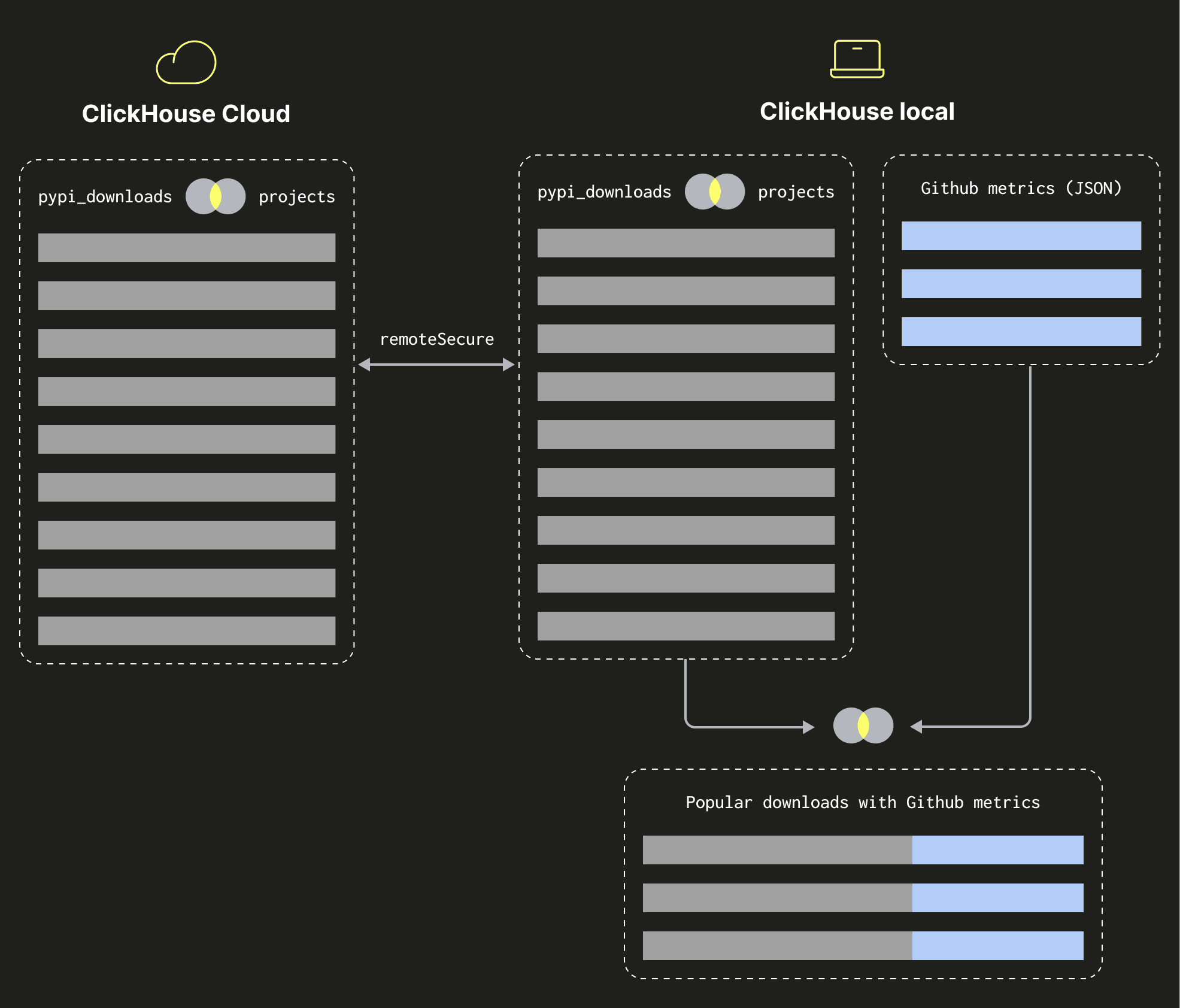
Apart from keras and transformers, most of the well downloaded packages don’t appear on our list. We can find out how many stars those packages have by changing the ORDER BY clause to sort by downloads instead of stars. We need to change the following line: \
ORDER BY stars DESC
To be:
ORDER BY count DESC
And if we run the query with that change, we’ll see the following output:
┌─projects.name──────┬─repository─────────────────┬───────count─┬─stars─┐
│ boto3 │ boto/boto3 │ 16031894410 │ 8440 │
│ botocore │ boto/botocore │ 11033306159 │ 1352 │
│ certifi │ certifi/python-certifi │ 8606959885 │ 707 │
│ s3transfer │ boto/s3transfer │ 8575775398 │ 189 │
│ python-dateutil │ dateutil/dateutil │ 8144178765 │ 2164 │
│ charset-normalizer │ Ousret/charset_normalizer │ 5891178066 │ 448 │
│ jmespath │ jmespath/jmespath.py │ 5405618311 │ 1975 │
│ pyasn1 │ pyasn1/pyasn1 │ 5378303214 │ 18 │
│ google-api-core │ googleapis/python-api-core │ 5022394699 │ 98 │
│ importlib-metadata │ python/importlib_metadata │ 4353215364 │ 101 │
└────────────────────┴────────────────────────────┴─────────────┴───────┘
10 rows in set. Elapsed: 3.957 sec. Processed 11.96 million rows, 941.07 MB (3.02 million rows/s., 237.81 MB/s.)
Peak memory usage: 336.19 MiB.
There’s not much love for most of these projects on GitHub! The query still takes 4 seconds, but with this one we can speed it up because we’re sorting by a field that’s on the remote table. This means that we could restrict the number of records being returned by the remote join, as shown in the diagram below:
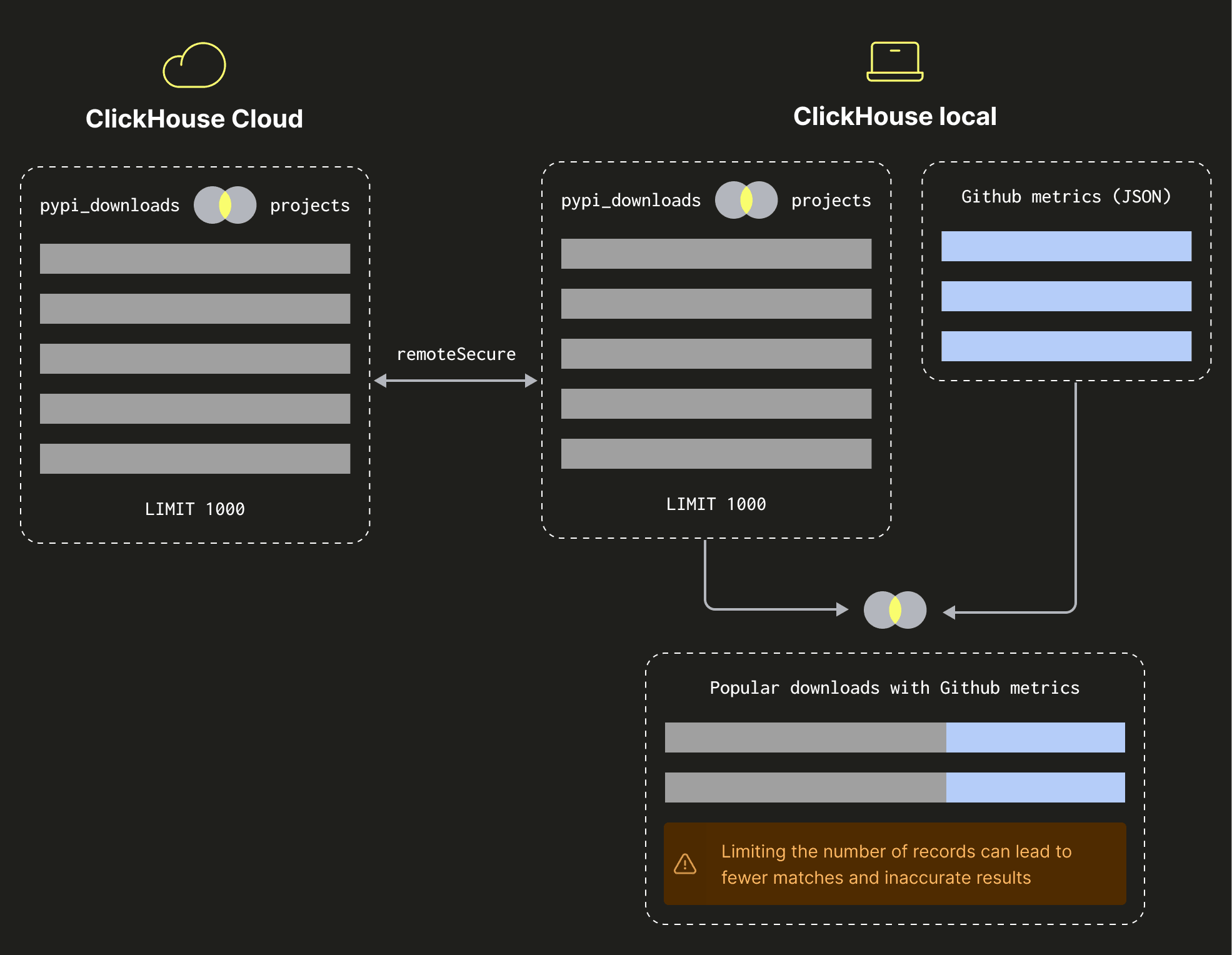
Let’s restrict the number of records to 1,000, as shown in the query below:
WITH pypiProjects AS (
SELECT home_page, projects.name, sum(count) AS count
FROM remoteSecure(
'clickpy-clickhouse.clickhouse.com',
'pypi.pypi_downloads',
'mark', {password:String}
) AS pypi_downloads
INNER JOIN
(
SELECT name, argMax(home_page, version) AS home_page
FROM remoteSecure(
'clickpy-clickhouse.clickhouse.com',
'pypi.projects',
'mark', {password:String}
)
GROUP BY name
) AS projects ON projects.name = pypi_downloads.project
GROUP BY ALL
ORDER BY count DESC
LIMIT 1000
)
SELECT
name,
replaceOne(home_page, 'https://github.com/', '') AS repository,
count,
gh.stargazers_count AS stars
FROM pypiProjects
INNER JOIN
(
SELECT *
FROM file('data/*.json', JSONEachRow)
) AS gh ON gh.svn_url = pypiProjects.home_page
GROUP BY ALL
ORDER BY count DESC
LIMIT 10;
┌─name───────────────┬─repository─────────────────┬───────count─┬─stars─┐
│ boto3 │ boto/boto3 │ 16031894410 │ 8440 │
│ botocore │ boto/botocore │ 11033306159 │ 1352 │
│ certifi │ certifi/python-certifi │ 8606959885 │ 707 │
│ s3transfer │ boto/s3transfer │ 8575775398 │ 189 │
│ python-dateutil │ dateutil/dateutil │ 8144178765 │ 2164 │
│ charset-normalizer │ Ousret/charset_normalizer │ 5891178066 │ 448 │
│ jmespath │ jmespath/jmespath.py │ 5405618311 │ 1975 │
│ pyasn1 │ pyasn1/pyasn1 │ 5378303214 │ 18 │
│ google-api-core │ googleapis/python-api-core │ 5022394699 │ 98 │
│ importlib-metadata │ python/importlib_metadata │ 4353215364 │ 101 │
└────────────────────┴────────────────────────────┴─────────────┴───────┘
10 rows in set. Elapsed: 1.758 sec. Processed 2.08 thousand rows, 14.97 MB (1.18 thousand rows/s., 8.51 MB/s.)
Peak memory usage: 448.22 MiB.
This time it takes just under 2 seconds because we aren’t streaming so many records to ClickHouse Local before doing the join with the GitHub data. This isn’t a perfect solution, however, because we could have ended up with fewer than 10 records if more than 990 of our 1,000 records didn’t have a match in the GitHub dataset.
Summary
And that’s about it for now. I’d be curious to know what you all think? Can you see a real use case for this functionality? If so let us know in the comments or on ClickHouse Slack.


