The release train keeps on rolling.
We are super excited to share a bevy of amazing features in 23.5.
And, we already have a date for the 23.6 release, please register now to join the community call on June 29th at 9:00 AM (PDT) / 6:00 PM (CEST).
Release Summary
29 new features. 22 performance optimizations. 85 bug fixes.
A small subset of highlighted features are below. But it is worth noting that several features are now production ready or have been enabled by default. You can find those at the end of this post.
Azure Table Function (Alexander Sapin, Smita Kulkarni)
Experienced users of ClickHouse will be familiar with the s3 and gcs functions. These functions are almost identical from an implementation point of view, with the latter recently added simply to make it more intuitive for users looking to query Google GCS. Both allow the users to query files hosted in s3-based blob storage, either to query in-place or to use as a source of data for insertion into a ClickHouse MergeTree table.
While GCS is almost completely interoperable with S3, Azure’s equivalent blob storage offering deviates somewhat from the S3 specification and requires significantly more work.
In 23.5 we are pleased to announce the availability of the azureBlobStorage table function for querying Azure Blob Storage. Users can now query files in any of the supported formats in Azure Blob Storage. This function differs a little in its parameters from the S3 and GCS functions, but delivers similar capabilities. Note below how we are required to specify a connection string, container and blob path to align with Azure Blob storage concepts. In the examples below we query the UK price paid dataset.
SELECT
toYear(toDate(date)) AS year,
round(avg(price)) AS price,
bar(price, 0, 1000000, 80)
FROM azureBlobStorage('https://clickhousepublicdatasets.blob.core.windows.net/', 'ukpricepaid', 'uk_price_paid_*.parquet', 'clickhousepublicdatasets', '<key>')
GROUP BY year
ORDER BY year ASC
┌─year─┬──price─┬─bar(round(avg(price)), 0, 1000000, 80)─┐
│ 1995 │ 67938 │ █████▍ │
│ 1996 │ 71513 │ █████▋ │
│ 1997 │ 78543 │ ██████▎ │
│ 1998 │ 85443 │ ██████▊ │
│ 1999 │ 96041 │ ███████▋ │
│ 2000 │ 107493 │ ████████▌ │
│ 2001 │ 118893 │ █████████▌ │
│ 2002 │ 137958 │ ███████████ │
│ 2003 │ 155894 │ ████████████▍ │
│ 2004 │ 178891 │ ██████████████▎ │
│ 2005 │ 189362 │ ███████████████▏ │
│ 2006 │ 203535 │ ████████████████▎ │
│ 2007 │ 219376 │ █████████████████▌ │
│ 2008 │ 217044 │ █████████████████▎ │
│ 2009 │ 213424 │ █████████████████ │
│ 2010 │ 236115 │ ██████████████████▉ │
│ 2011 │ 232807 │ ██████████████████▌ │
│ 2012 │ 238384 │ ███████████████████ │
│ 2013 │ 256926 │ ████████████████████▌ │
│ 2014 │ 280027 │ ██████████████████████▍ │
│ 2015 │ 297287 │ ███████████████████████▊ │
│ 2016 │ 313551 │ █████████████████████████ │
│ 2017 │ 346516 │ ███████████████████████████▋ │
│ 2018 │ 351101 │ ████████████████████████████ │
│ 2019 │ 352923 │ ████████████████████████████▏ │
│ 2020 │ 377673 │ ██████████████████████████████▏ │
│ 2021 │ 383795 │ ██████████████████████████████▋ │
│ 2022 │ 397233 │ ███████████████████████████████▊ │
│ 2023 │ 358654 │ ████████████████████████████▋ │
└──────┴────────┴────────────────────────────────────────┘
29 rows in set. Elapsed: 9.710 sec. Processed 28.28 million rows, 226.21 MB (2.91 million rows/s., 23.30 MB/s.)
With any table function, it often makes sense to expose an equivalent table engine for use cases where users wish to query a datasource like any other table. As shown, this simplifies subsequent queries:
CREATE TABLE uk_price_paid_azure
ENGINE = AzureBlobStorage('https://clickhousepublicdatasets.blob.core.windows.net/', 'ukpricepaid', 'uk_price_paid_*.parquet', 'clickhousepublicdatasets', '<key>')
SELECT
toYear(toDate(date)) AS year,
round(avg(price)) AS price,
bar(price, 0, 1000000, 80)
FROM uk_price_paid_azure
GROUP BY year
ORDER BY year ASC
┌─year─┬──price─┬─bar(round(avg(price)), 0, 1000000, 80)─┐
│ 1995 │ 67938 │ █████▍ │
│ 1996 │ 71513 │ █████▋ │
│ 1997 │ 78543 │ ██████▎ │
29 rows in set. Elapsed: 4.007 sec. Processed 28.28 million rows, 226.21 MB (7.06 million rows/s., 56.46 MB/s.)
Similar to the S3 and GCS functions, we can also use these functions to write ClickHouse data to an Azure Blob storage container, helping to address export and reverse ETL use cases.
INSERT INTO FUNCTION azureBlobStorage('https://clickhousepublicdatasets.blob.core.windows.net/', 'ukpricepaid', 'uk_price_paid_{_partition_id}.parquet', 'clickhousepublicdatasets', '<key>') PARTITION BY toYear(date) SELECT * FROM uk_price_paid;
In the above example, we use the PARTITION BY clause and toYear function and to create a Parquet file per year.
Hopefully this function unlocks projects for our users. The above function is limited in the sense it executes only on the receiving node, restricting the level of compute which can be assigned to a query. To address this we are actively working on an azureBlobStorageCluster function. This will be conceptually equivalent to s3Cluster which distributes processing of files in an S3 bucket across a cluster by exploiting glob patterns. Stay tuned (and join release webinars) for updates!
We'd like to thank Jakub Kuklis who contributed the VFS level integration with Azure in 2021, with review and support provided by Kseniia Sumarokova.
ClickHouse Keeper Client (Artem Brustovetskii)
Last year we released ClickHouse Keeper to provide strongly consistent storage for data associated with ClickHouse's cluster coordination system and is fundamental to allowing ClickHouse to function as a distributed system. This supports services such as data replication, distributed DDL query execution, leadership elections, and service discovery. ClickHouse Keeper is compatible with ZooKeeper, the legacy component used for this functionality in ClickHouse.
ClickHouse Keeper is production ready. ClickHouse Cloud is running clickhouse-keeper at large scale to support thousands of ClickHouse deployments in a multi-tenant environment.
Until now users would communicate with ClickHouse Keeper by sending commands directly over TCP using tools such as nc or zkCli.sh. While sufficient for basic debugging, this made administrative tasks a less than ideal user experience and were far from convenient. To address this, in 23.5 we introduce keeper-client - a simple tool built into ClickHouse for introspecting your ClickHouse Keeper.
To experiment with the client we can use our recently released docker compose files, courtesy of our support team, to quickly start a multi-node ClickHouse cluster. In the example below, we start a 2 node deployment with a single replicated shard and 3 keeper instances:
[email protected]:ClickHouse/examples.git
export CHKVER=23.5
export CHVER=23.5
cd examples/docker-compose-recipes/recipes/cluster_1S_2R/
docker-compose up
The above exposes our keeper instances on ports 9181, 9182 and 9183. Connecting with the client is as simple as:
./clickhouse keeper-client -h 127.0.0.1 -p 9181
/ :) ruok
imok
/ :) ls
clickhouse keeper
/ :)
Users can also exploit a --query parameter, similar to the ClickHouse Client, for bash scripting.
./clickhouse keeper-client -h 127.0.0.1 -p 9181 --query "ls/"
clickhouse keeper
Further available options can be found here.
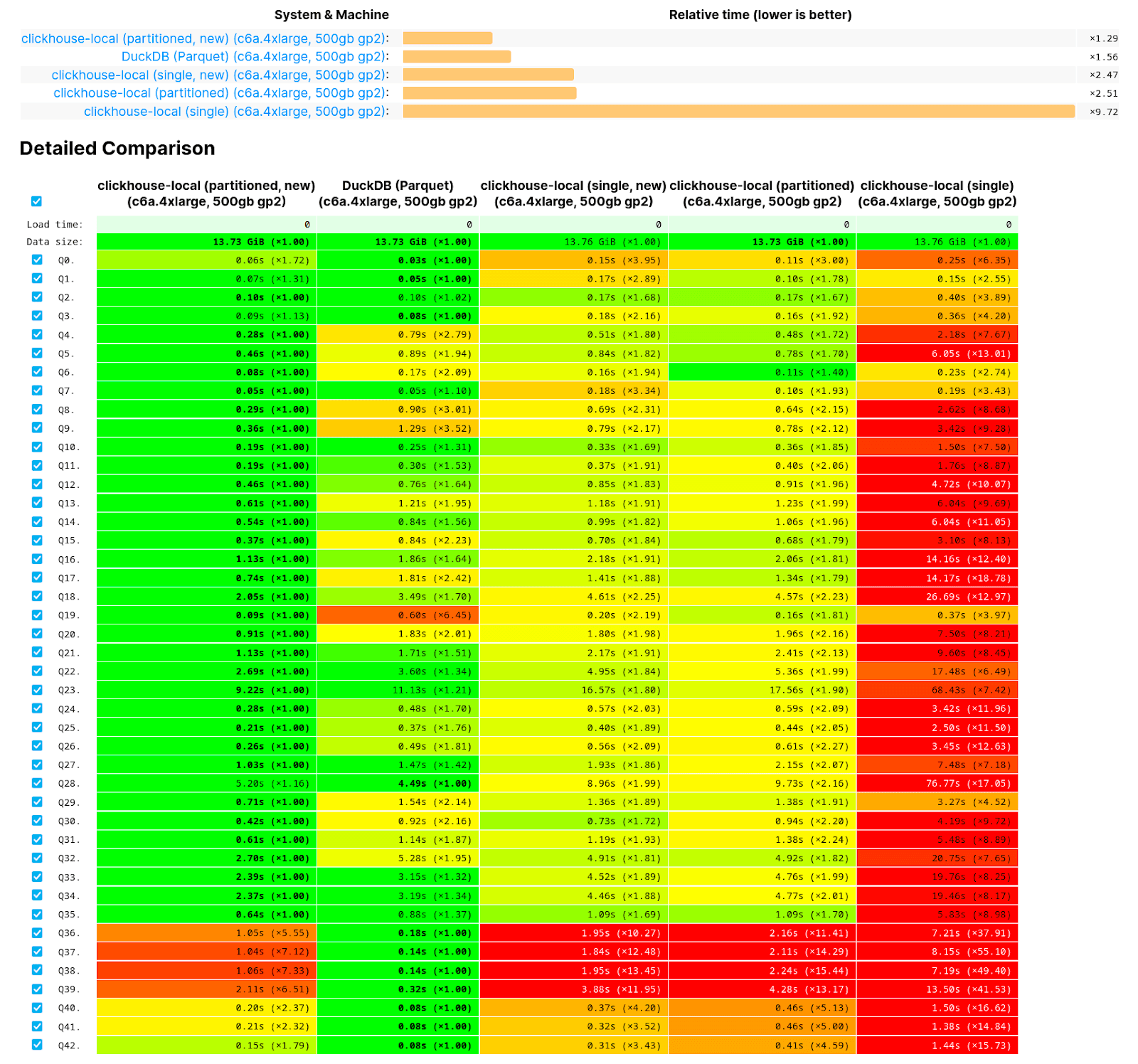
Parquet reading even faster (Michael Kolupaev)
Recently we blogged about the improvements we’ve made with respect to the querying of Parquet files. These were the start of what we consider to be a journey in making ClickHouse the world’s fastest tool for querying Parquet files, either via ClickHouse Local or ClickHouse Server. Unsatisfied with recent efforts to parallelise reading of Parquet, by exploiting row groups, 23.5 adds further improvements.
Most of these improvements related to low level efforts to make parallel reading more efficient by avoiding mutex locks. As noted in our blog, we also historically read Parquet rows in order which inherently limits reading speed. This limitation is now removed, with out of order reading the default. While this is not expected to impact most users (other than their queries being faster!), as analytical queries typically do not depend on read order, users can revert to the old behavior if required via the setting input_format_parquet_preserve_order = true.
As an example of the improvements, consider the following case of executing the earlier query over a single Parquet file containing all of the rows from the earlier UK price paid dataset - this file can be downloaded from here.
--23.4
SELECT
toYear(toDate(date)) AS year,
round(avg(price)) AS price,
bar(price, 0, 1000000, 80)
FROM file('house_prices.parquet')
GROUP BY year
ORDER BY year ASC
29 rows in set. Elapsed: 0.367 sec.
--23.5
SELECT
toYear(toDate(date)) AS year,
round(avg(price)) AS price,
bar(price, 0, 1000000, 80)
FROM file('house_prices.parquet')
GROUP BY year
ORDER BY year ASC
29 rows in set. Elapsed: 0.240 sec.
For users writing Parquet files based on data in ClickHouse, there are three main approaches - using INTO OUTFILE, INSERT INTO FUNCTION or by simply redirecting SELECT FORMAT Parquet to a file. Historically we have recommended users utilize the latter of these two approaches, principally because INTO OUTFILE could reproduce very large row group sizes due to some less than ideal internal behaviors. This would impact later read performance. This could be a complex issue to debug and would require a deep understanding of Parquet. Fortunately, this issue is now addressed - feel free to use INTO OUTFILE as you might for other formats!
While the above all represent significant improvements, this journey is still not complete. There are still queries we need to further improve - specifically the querying of single large Parquet files. For those interested, follow our open benchmarks for Parquet at ClickBench.
Wrap up
As mentioned in the introduction, several features are now enabled by default or considered production ready (no longer experimental). In particular, geographical data types (Point, Ring, Polygon, MultiPolygon) and functions (distance, area, perimeter, union, intersection, convex hull, etc) are now production ready in 23.5!
In addition, compressed marks and indices on disk (first available in 22.9) are now available by default. The first query after server startup has never been faster.
Last, but definitely not least, the Query Results Cache is now considered ‘production ready’. We have written, at length, about the feature in a post titled Introducing the ClickHouse Query Cache. The query cache is based on the idea that sometimes there are situations where it is okay to cache the result of expensive SELECT queries such that further executions of the same queries can be served directly from the cache.
New Contributors
A special welcome to all the new contributors to 23.5! ClickHouse's popularity is, in large part, due to the efforts of the community who contributes. Seeing that community grow is always humbling.
If you see your name here, please reach out to us...but we will be finding you on twitter, etc as well.
Alexey Gerasimchuck, Alexey Gerasimchuk, AnneClickHouse, Duyet Le, Eridanus, Feng Kaiyu, Ivan Takarlikov, Jordi, János Benjamin Antal, Kuba Kaflik, Li Shuai, Lucas Chang, M1eyu2018, Mal Curtis, Manas Alekar, Misz606, Mohammad Arab Anvari, Raqbit, Roman Vlasenko, Sergey Kazmin, Sergey Kislov, Shane Andrade, Sorck, Stanislav Dobrovolschii, Val Doroshchuk, Valentin Alexeev, Victor Krasnov, Vincent, Yusuke Tanaka, Ziy1-Tan, alekar, auxten, cangyin, darkkeks, frinkr, ismailakpolat, johanngan, laimuxi, libin, lihaibo42, mauidude, merlllle, ongkong, sslouis, vitac, wangxiaobo, xmy, zy-kkk, 你不要过来啊


