Part 2 of this blog can be found at Change Data Capture (CDC) with PostgreSQL and ClickHouse - Part 2.
Table of Contents
Introduction
In previous posts, we have discussed the differences between OLTP databases, such as Postgres, and OLAP databases, such as ClickHouse, and why users may wish to move analytical workloads to the latter.
This post provides an introductory guide to achieving Change Data Capture with Postgres and ClickHouse. For those unfamiliar, Change Data Capture (CDC) is the process by which tables are kept in sync between two databases. The solution proposed by this blog series uses only the native features of ClickHouse. No additional components are required other than Debezium and Kafka.
This initial post introduces the concepts and building blocks for a Postgres to ClickHouse CDC pipeline. The next post in this series will assemble these concepts and produce a working pipeline. While the latter blog post can potentially be consumed independently of this one, we recommend users read this post to understand the concepts and constraints to avoid possible issues.
For our examples, we use a development instance in ClickHouse Cloud cluster and an AWS Aurora instance of Postgres. These examples should, however, be reproducible on an equivalently sized self-managed cluster. Alternatively, start your ClickHouse Cloud cluster today, and receive $300 of credit. Let us worry about the infrastructure and get querying!
Approaches
CDC can be simple in cases where data is either static or immutable and only subject to appends. Often native ClickHouse functions such as the postgresql function are sufficient for moving data between the instances, using a timestamped or monotonically increasing id to periodically identify which rows need to be read from the OLTP database and inserted into ClickHouse.
However, for tables that are subject to more complex workloads containing updates and deletes, users need to identify and track all of these possible changes in their source Postgres database in order to apply them to ClickHouse in near real-time.
Solutions to this problem are often specific to both the source and destination, exploiting features of the former to identify changes and ensuring these are reflected as efficiently as possible in the destination based on its optimal usage patterns. We describe a few approaches to this below.
Pull-based
With pull-based Change Data Capture, the destination database pulls changes from the source, typically using logged changes to a tables column. This places less load on the source and requires a polling method to be implemented from the target.
In cases where the data is immutable and append-only, a cron-scheduled postgresql function that moves data between Postgres and ClickHousecould be considered as a pull implementation.
Users can optionally add a messaging system to ensure the delivery of changes is robust, even if the target system is unavailable. As changes are periodically batched and applied, this approach principally suffers from a delay between the visibility of changes in the source and destination. Additionally, this approach requires network access to the source database, which has no control over when and how data is pulled. This is often undesirable in production-critical systems where administrators are hesitant to provide access.
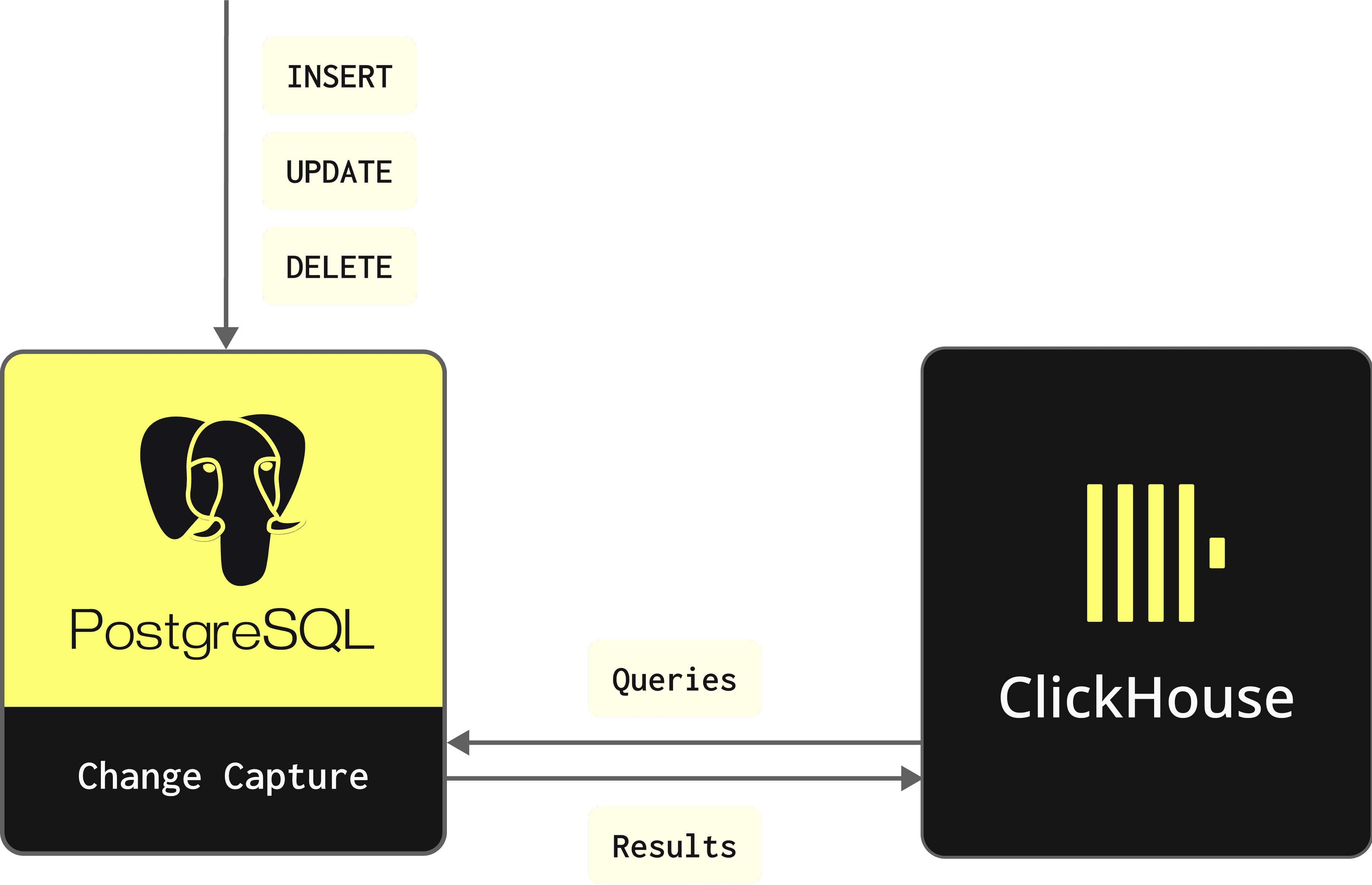
Push via real-time event streaming
In a push-based Change Data Capture pipeline, the source system captures changes to columns for a table and sends these to the target system, where they will be applied to the current data. At any point in time, the two systems should be almost identical, with changes applied in almost real-time. This approach assumes a reliable delivery of changes is possible - either through exactly-once delivery semantics or through at-least-once delivery and the ability of the destination to handle duplicates appropriately. While not necessarily essential, this method will often introduce a messaging system such as Kafka to ensure reliable message delivery.

Below, we propose a push-based approach to CDC for moving changes between Postgres and ClickHouse in near real time. To achieve this, we exploit the native features of Postgres, which identify changes occurring at a storage level and convert these into a stream of consumable changes.
Tracking changes in PostgreSQL
Any CDC solution requires the source database to provide a robust and reliable means of tracking changes to specific tables at the row and column level. PostgreSQL exposes these changes through two foundational features:
- The Write-Ahead Log (WAL) is a sequential log of all changes made to the database. Whenever a transaction modifies the database, the changes are first written to the WAL before being applied to the actual data files. This process is known as write-ahead logging. This provides durability and crash recovery for database transactions. It is a critical component of PostgreSQL's transaction processing mechanism. By using WAL, PostgreSQL ensures that changes are durably stored on disk before considering a transaction as committed. The WAL is also crucial for various replication techniques in PostgreSQL, which use the WAL to capture changes made on the primary database and apply them to the replicas, ensuring consistency across multiple database instances. However, in its native format, this log is not optimized for external processes and is thus challenging to consume.
- Logical decoding in Postgres decodes the contents of the WAL into a coherent and easy-to-understand format, such as a stream of tuples or SQL statements. This requires the use of replication slots, which represent a stream of in-order changes, typically used to replay events between a client and server for normal Postgres replication. Crucially, these replication slots ensure changes are delivered in the order in which they were applied to the source database. This ordering is based on an internal LSN (Log Sequence Number), itself a pointer to a position in the WAL log. This process is robust to crashes, using checkpoints to advance the position. Critically, any consumer must be able to potentially handle duplicate messages delivered due to a restart between checkpoints (Postgres will return to an earlier checkpointed LSN position).
The decoding process performed by Logical decoding, and the subsequent format of messages in the replication slot, can be controlled through a plugin. While other options exist, since version 10 Postgres has included a standard logical decoding plugin pgoutput that requires no additional libraries to be installed and is also used for internal replication. With this stream of change messages available, we now need a system capable of reading them and sending them to ClickHouse. For this, we will use the open-source tool Debezium.
Debezium
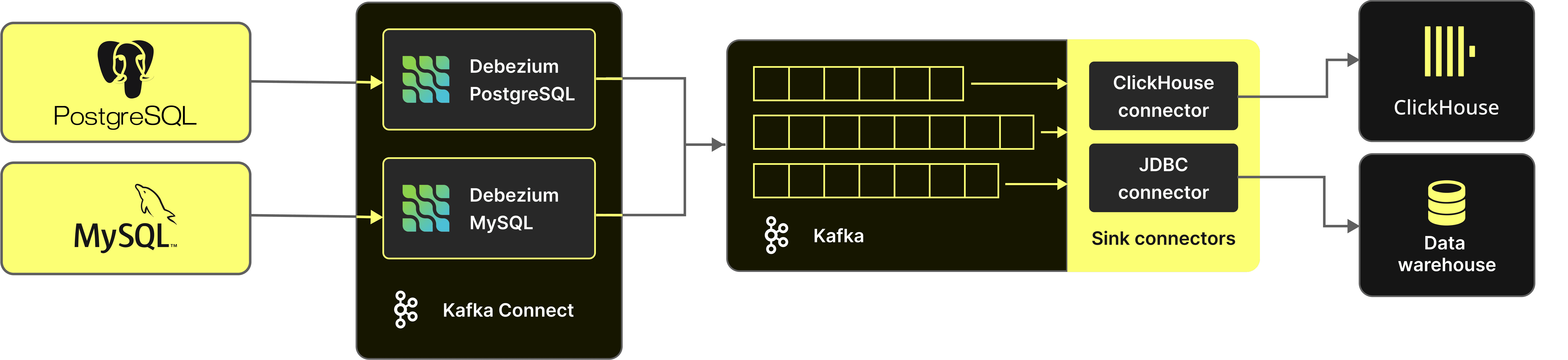
Debezium is a set of services for capturing changes in a database. Debezium records all row-level changes within a database table as an ordered event stream, sending these to downstream systems for consumption. Supporting a library of connectors, Debezium aims to produce messages in a format independent of the source DBMS thus allowing similar logic to be employed by the consumer of the events irrespective of the origin. While we have yet to test other database connectors, such as MySQL and MSSQL, this should mean the following ClickHouse configuration should be reusable.
This architecture requires each connector to exploit the appropriate change capture features in each source database. In the case of Postgres, the connector exploits the Logical decoding feature and messages exposed through a replication slot, described above. This is coupled with custom Java code which uses the JDBC driver and streaming replication protocol to read the stream of changes and generate events. In a standard architecture, these events are sent to Kafka for consumption by downstream sinks.
In summary, Debezium will produce a row change event for every insert, update and delete that occurs in Postgres. These events must then be applied to an equivalent table in our ClickHouse instance to ensure our data is consistent. Note that the mapping of tables here is 1:1. In its simplest form, a Debezium connector is deployed per table, although multi-table configurations are possible.
Kafka and the role of a queue
A messaging system is typically implemented between the source and target systems so that change events can be buffered and kept until they are committed to the destination. This queue relieves pressure from Postgres’ Write-Ahead Log and decouples the systems. This avoids potential issues with the Postgres WAL log growing as it cannot be reclaimed (it is not held indefinitely and can be trimmed once events are no longer needed) in the event ClickHouse is unavailable e.g. due to network connectivity issues .
Developed using the Kafka Connect framework, Debezium inherently supports Apache Kafka making it the obvious messaging system of choice for our CDC solution - especially when combined with the rich options for integrating Kafka with ClickHouse. Deploying and configuring Kafka is beyond the scope of this blog, but the Debezium docs include recommendations on topic configuration and naming.
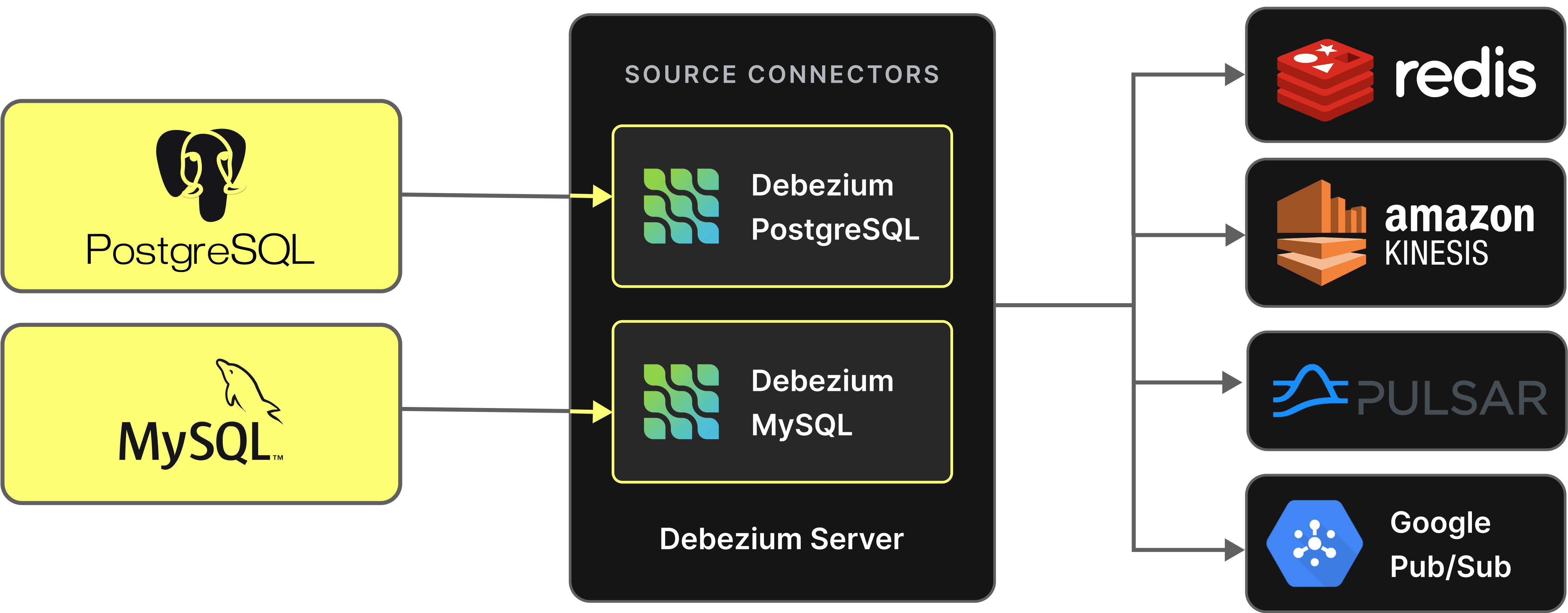
Note that Debezium also supports a Server mode, where events can be sent to any messaging system such as Kinesis or Google Pub Sub. While we haven’t tested these architectures, provided the Debezium and Postgres configurations remain identical and the resulting messages use the same format, users should be able to use the same ClickHouse configuration and approach to CDC.
ReplacingMergeTree
Above, we described how Debezium is capable of producing a stream of insert, update and delete events from Postgres by exploiting the WAL log via the pgoutput plugin and a replication slot.
With this stream of messages available, we describe how to apply these changes to ClickHouse. Since ClickHouse is not optimized yet for delete and update workloads, we use the ReplacingMergeTree table engine to handle this change stream efficiently. As part of this, We also discuss some of the important considerations of using this table engine, as well as recent developments and under what conditions this approach will work optimally.
Optimizing deletes and updates
While OLTP databases such as Postgres are optimized for transactional update and delete workloads, OLAP databases offer reduced guarantees for such operations and optimize for immutable data inserted in batches for the benefit of significantly faster analytical queries. While ClickHouse offers update operations through mutations, as well as a lightweight means of deleting row, its column-orientated structure means these operations should be scheduled with care. These operations are handled asynchronously, processed with a single thread, and require (in the case of updates) data to be rewritten on disk. They should thus not be used for high numbers of small changes.
In order to process a stream of update and delete rows while avoiding the above usage patterns, we can use the ClickHouse table engine ReplacingMergeTree.
This table engine allows update operations to be applied to rows, without needing to use inefficient ALTER or DELETE statements, by offering the ability for users to insert multiple copies of the same row and denote one as the latest version. A background process in turn asynchronously removes older versions of the same row, efficiently imitating an update operation through the use of immutable inserts.
This relies on the ability for the table engine to identify duplicate rows. This is achieved using an ORDER BY clause to determine uniqueness, i.e., if two rows have the same values for the columns specified in the ORDER BY, they are considered duplicates. A version column, specified when defining the table, allows the latest version of a row to be retained when two rows are identified as duplicates i.e. the row with the highest version value is kept.
Additionally, a deleted column can be specified. This can contain either 0 or 1, where a value of 1 indicates that the row (and its duplicates) should be removed and zero is used otherwise.
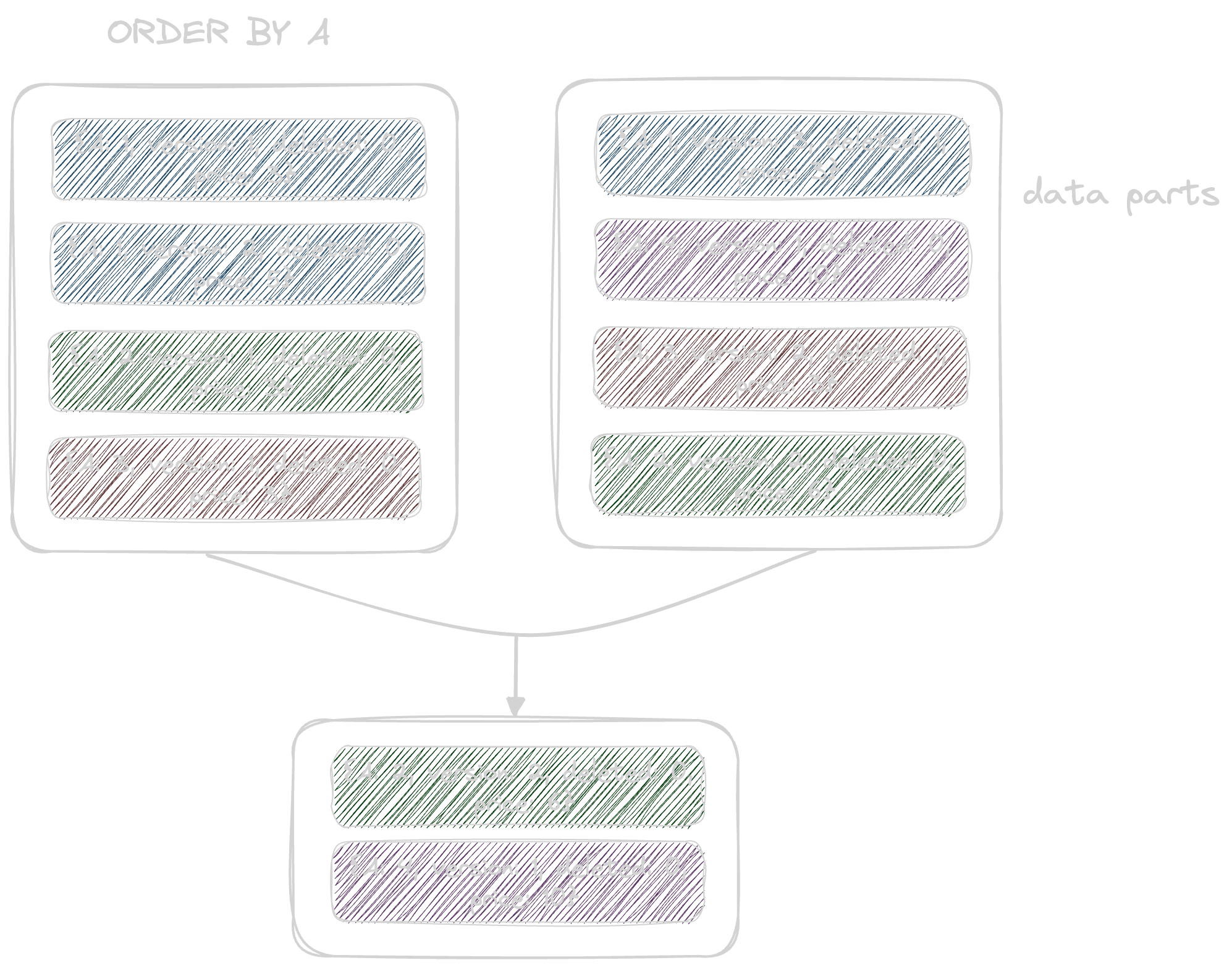
We illustrate this process in the example below. Here the rows are uniquely identified by the A column (the ORDER BY for the table). We assume these rows have been inserted as two batches, resulting in the formation of two data parts on disk. Later, during an asynchronous background process, these parts are merged together. During this process, the following occurs:
- The row identified by the value 1 for the column
Ahas both an update row, with version 2, and a delete row with version 3 (anddeletedcolumn value of 1). All rows for this key are therefore removed. - The row identified by the value 2 for the column
Ahas both an update row, with version 2. This latter row, with a value of 6 for thepricecolumn, is therefore retained. - The row identified by the value 3 for the column
Ahas both an update row, with version 2. This latter row, with a value of 3 for thepricecolumn, is therefore retained.
As a result of this merge process, we have two rows representing the final state.
As described, this duplicate removal process occurs at merge time, asynchronously in the background, and is eventually consistent only. Alternatively, it can be invoked at query time using the special FINAL syntax to ensure results are accurate - see Querying in ClickHouse.
As well as being useful for duplicate removal, the properties of this table engine can be used to handle update and delete workloads. Suppose we have the following simple table and row in ClickHouse. Note how the ORDER BY clause defines row uniqueness and is set to the column key. We also have a version and deleted column defined as part of the engine create statement:
CREATE TABLE test
(
`key` String,
`price` UInt64,
`version` UInt64,
`deleted` UInt8
)
ENGINE = ReplacingMergeTree(version, deleted)
ORDER BY key
{"version":1,"deleted":0,"key":"A","price":100}
Suppose we needed to update the price column (as its changed in Postgres) of this row. To achieve this we insert the following row. Note how the key value is identical and but how the version value has been incremented.
{"version":2,"deleted":0,"key":"A","price":200}
If we later wished to delete this row, we would again insert a duplicate with the same key value, a higher version and a value of 1 for the deleted column.
{"version":3,"deleted":1,"key":"A","price":200}
This method of update and deletes allows us to explicitly avoid inefficient ALTER and DELETE commands, instead simulating these operations by inserting immutable rows and allowing ClickHouse to asynchronously reconcile the changes.
Limitations with deletes
Removing deleted rows
Deleted rows are only removed at merge time if the table level setting clean_deleted_rows is set to Always. By default, this value is set to Never, which means rows will never be deleted. As of ClickHouse version 23.5, this feature has a known issue when the value is set to Always, causing the wrong rows to be potentially removed.
Therefore, at present, we recommend using the value Never as shown - this will cause deleted rows to accumulate, which may be acceptable at low volumes. To forcibly remove deleted rows, users can periodically schedule an OPTIMIZE FINAL CLEANUP operation on the table i.e.
OPTIMIZE TABLE uk_price_paid FINAL CLEANUP
This is an I/O intensive operation and should be scheduled with care during idle periods.
For this reason, until the above issue is addressed, we recommend our CDC pipeline only for tables with a low to moderate number of deletes (less than 10%).
In order delivery only
If supporting deletes and relying on either OPTIMIZE FINAL CLEANUP or clean_deleted_rows=Always (when the above issue is addressed) to remove rows, then changes must be delivered in order for each Postgres row. More specifically, the rows for a distinct set of values for the configured ORDER BY columns must be inserted in the order in which they occurred in Postgres.
If this constraint is not satisfied, then rows can be incorrectly retained, if an update occurs after a delete has been actioned by a background merge or scheduled OPTIMIZE FINAL CLEANUP. Consider the following sequence of events:
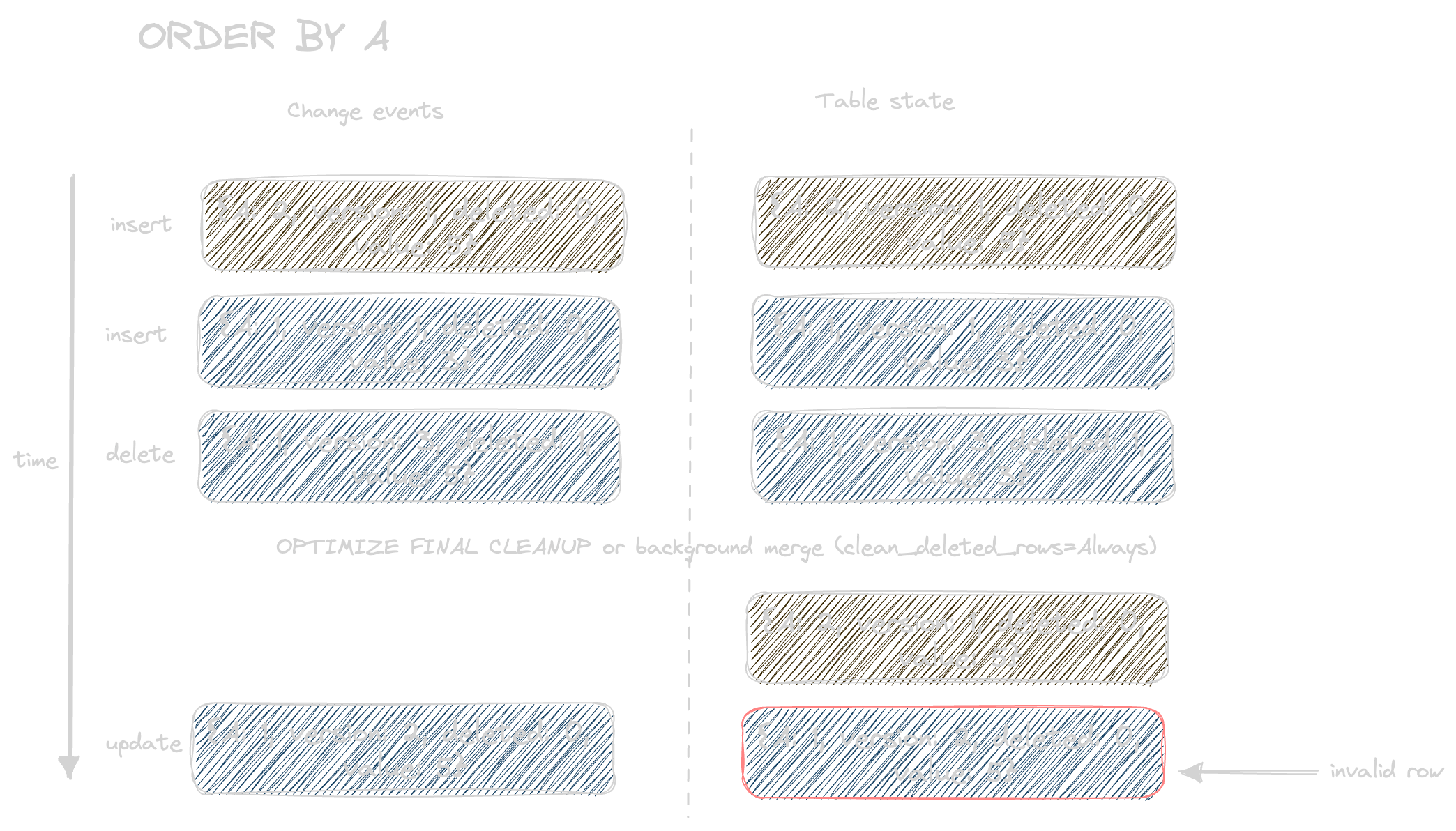
As shown above, an insert is received for row unique key value A followed by a delete event. An OPTIMIZE FINAL CLEANUP, or background merge, occurs causing both rows to be removed. An update event is in turn received with a lower version than the previous delete, due to out of order insertion. This row is retained incorrect. This issue can be replicated simply. Note that this issue does not occur if clean_deleted_rows=Never, as currently recommended, as deleted rows are preserved.
To address this, Debezium uses a single partition for its Kafka topic by default, thus ensuring in-order delivery (as well as using only one Kafka task). While this is sufficient for most workloads, higher throughputs may require multiple partitions.
If multiple partitions are required, users may wish to explore topic partition routing, hashing the ORDER BY columns to ensure all change events for the same row go to the same partition, thus guaranteeing in-order delivery. While this does not guarantee in-order delivery across all events, it ensures the changes are delivered in order for a specific Postgres row and set of ORDER BY values - sufficient to avoid the above race condition. Note: we have not tested this multi-topic configuration.
Alternatively, users can avoid using OPTIMIZE FINAL CLEANUP and simply allow deleted rows to accumulate or ensure it is executed carefully, e.g., pause changes on Postgres, allow the Kafka queue to clear, perform a clean-up of deletes before commencing changes against Postgres. Users may also be able to issue OPTIMIZE FINAL CLEANUP against selective partitions no longer subject to changes.
Row requirements
Thus, in order for our Postgres to ClickHouse Change Data Capture pipeline to work with updates and deletes, any rows sent to ClickHouse thus need to satisfy the following:
- The values of the columns in the ClickHouse
ORDER BYclause must uniquely identify a row in Postgres. - When any change event row is sent, whether an update or delete, it must contain the same values for the columns in the ORDER BY clause, which uniquely identifies the row. These values cannot change and should be considered immutable. The
ORDER BYclause will usually contain the primary key column in Postgres. Users will also want to include columns that align with query access patterns to optimize query performance. Updates cannot change these columns - see Choosing a Primary Key. - When an updated row is sent, it must contain all of the columns from the table with the final state of the row as values, as well as a value of 0 for the
deletedcolumn and aversionvalue higher than the preceding rows. - When a delete row is sent, it must contain all of the columns for the
ORDER BY clauseand a value of 1 for the deleted column, as well as a higher value for theversioncolumn than previous columns. - Inserts must contain all column values, a value of 0 for the
deletedcolumn, and aversionnumber which will be guaranteed to be lower than subsequent updates.
Change events for Postgres rows can be sent independently to ClickHouse. If users are allowing deleted rows to accumulate, change events for a specific row can also be sent out of order. If delete events are to be removed, change events must occur in order for any specific Postgres row as described above (but not across Postgres rows). These constaints must be considered when designing a multi-threaded/process approach to consuming messages from Kafka.
All of the above requires a version number that satisfies the required properties of ensuring it is monotonically increasing and reflective of the order of events in Postgres for a specific row.
In our next post, we will discuss how we can transform Debezium's change event messages to satisfy the above requirements of the ReplacingMergeTree.
Choosing a primary key
Above, we highlighted an important additional constraint that must also be satisfied in the case of the ReplacingMergeTree: the values of columns of the ORDER BY uniquely identify a Postgres row across changes. The Postgres primary key should thus be included in the Clickhouse ORDER BY clause.
Users of ClickHouse will be familiar with choosing the columns in their tables ORDER BY clause to optimize for query performance. Generally, these columns should be selected based on your frequent queries and listed in order of increasing cardinality. Importantly, the ReplacingMergeTree imposes an additional constraint - these columns must be immutable, i.e., only add columns to this clause that do not change in the underlying Postgres data. While other columns can change, these are required to be consistent for unique row identification.
For analytical workloads, the Postgres primary key is generally of little use as users will rarely perform point row lookups (something OLAP databases are not optimized for, unlike OLTP databases). Given we recommend that columns be ordered in order of increasing cardinality, as well as the fact that matches on columns listed earlier in the ORDER BY will usually be faster, the Postgres primary key should be appended to the end of the ORDER BY (unless it has analytical value). In the case that multiple columns form a primary key in Postgres, they should be appended to the ORDER BY, respecting cardinality and the likelihood of query value. Users may also wish to generate a unique primary key using a concatenation of values via a MATERIALIZED column.
Consider the following schema for the UK property prices dataset. Here the id column represents the unique primary key in Postgres (added to the dataset for example purposes). The columns postcode1, postcode2, addr1, addr2 represent columns commonly used in analytical queries. The id column is thus appended to the end of the ORDER BY clause with these preceding.
CREATE TABLE default.uk_price_paid
(
`id` UInt64,
`price` UInt32,
`date` Date,
`postcode1` LowCardinality(String),
`postcode2` LowCardinality(String),
`type` Enum8('other' = 0, 'terraced' = 1, 'semi-detached' = 2, 'detached' = 3, 'flat' = 4),
`is_new` UInt8,
`duration` Enum8('unknown' = 0, 'freehold' = 1, 'leasehold' = 2),
`addr1` String,
`addr2` String,
`street` LowCardinality(String),
`locality` LowCardinality(String),
`town` LowCardinality(String),
`district` LowCardinality(String),
`county` LowCardinality(String),
`version` UInt64,
`deleted` UInt8
)
ENGINE = ReplacingMergeTree(version, deleted)
PRIMARY KEY (postcode1, postcode2, addr1, addr2)
ORDER BY (postcode1, postcode2, addr1, addr2, id)
The ORDER BY clause configures the order of data on disk. By default, the PRIMARY KEY clause is also set to the same value if not specified. This clause configures the associated sparse primary index. The ORDER BY must include the PRIMARY KEY as a prefix, as the latter assumes the data is sorted.
For performance, this primary index is held in memory with a level of indirection using marks to minimize size. The use of the ORDER BY key for deduplication in the ReplacingMergeTree can cause this to become long, increasing memory usage. If this becomes a concern, users can specify the PRIMARY KEY directly, restricting those columns loaded into memory while preserving the ORDER BY to maximize compression and enforce uniqueness.
Using this approach, the Postgres primary key columns can be omitted from the PRIMARY KEY - saving memory without impacting query performance. We also apply this to our example above.
Querying in ClickHouse
At merge time, the ReplacingMergeTree identifies duplicate rows, using the ORDER BY values as a unique identifier, and either retains only the highest version or removes all duplicates if the latest version indicates a delete (pending the resolution of the earlier noted issue_. This, however, offers eventual correctness only - it does not guarantee rows will be deduplicated, and you should not rely on it. Queries can therefore produce incorrect answers due to update and delete rows being considered in queries.
To obtain correct answers, users will need to complement background merges with query time deduplication and deletion removal. This can be achieved using the FINAL operator. Consider the following examples using the UK property prices dataset.
postgres=> select count(*) FROM uk_price_paid;
count
----------
27735104
(1 row)
postgres=> SELECT avg(price) FROM uk_price_paid;
avg
---------------------
214354.531780374791
(1 row)
– no FINAL, incorrect result
SELECT count()
FROM uk_price_paid
┌──count()─┐
│ 27735966 │
└──────────┘
– FINAL, correct result
SELECT count()
FROM uk_price_paid
FINAL
┌──count()─┐
│ 27735104 │
└──────────┘
– no FINAL, incorrect result
SELECT avg(price)
FROM uk_price_paid
┌─────────avg(price)─┐
│ 214353.94542901445 │
└────────────────────┘
– FINAL, correct result with some precision
SELECT avg(price)
FROM uk_price_paid
FINAL
┌────────avg(price)─┐
│ 214354.5317803748 │
└───────────────────┘
FINAL performance
The FINAL operator will have a performance overhead on queries, despite improvements in 22.6 which ensured the deduplication step was multi-threaded. This will be most appreciable when queries are not filtering on primary key columns, causing more data to be read and increasing the deduplication overhead. If users filter on key columns using a WHERE condition, the data loaded and passed for deduplication will be reduced.
If the WHERE condition does not use a key column, ClickHouse does not currently utilize the PREWHERE optimization when using FINAL. This optimization aims to reduce the rows read for non-filtered columns. When a query runs, the granules required for reading are first identified using the table's primary key. This identifies a set of granules, each containing a number of rows (8192 by default). However, not all of the rows inside these granules will match the filter clause on the primary keys - since a granule can contain a range of values or because the WHERE condition does not use the primary key. In order to identify the correct rows and before the SELECT columns can be read, additional filtering is therefore desirable. This is performed in a 2nd stage of reading using PREWHERE, which allows both the primary and non-primary key columns in the WHERE clause to be further filtered. ClickHouse normally moves columns to the PREWHERE stage based on internal heuristics. However, this optimization is not currently applied when using FINAL. Further details on recent improvements for PREWHERE are here.
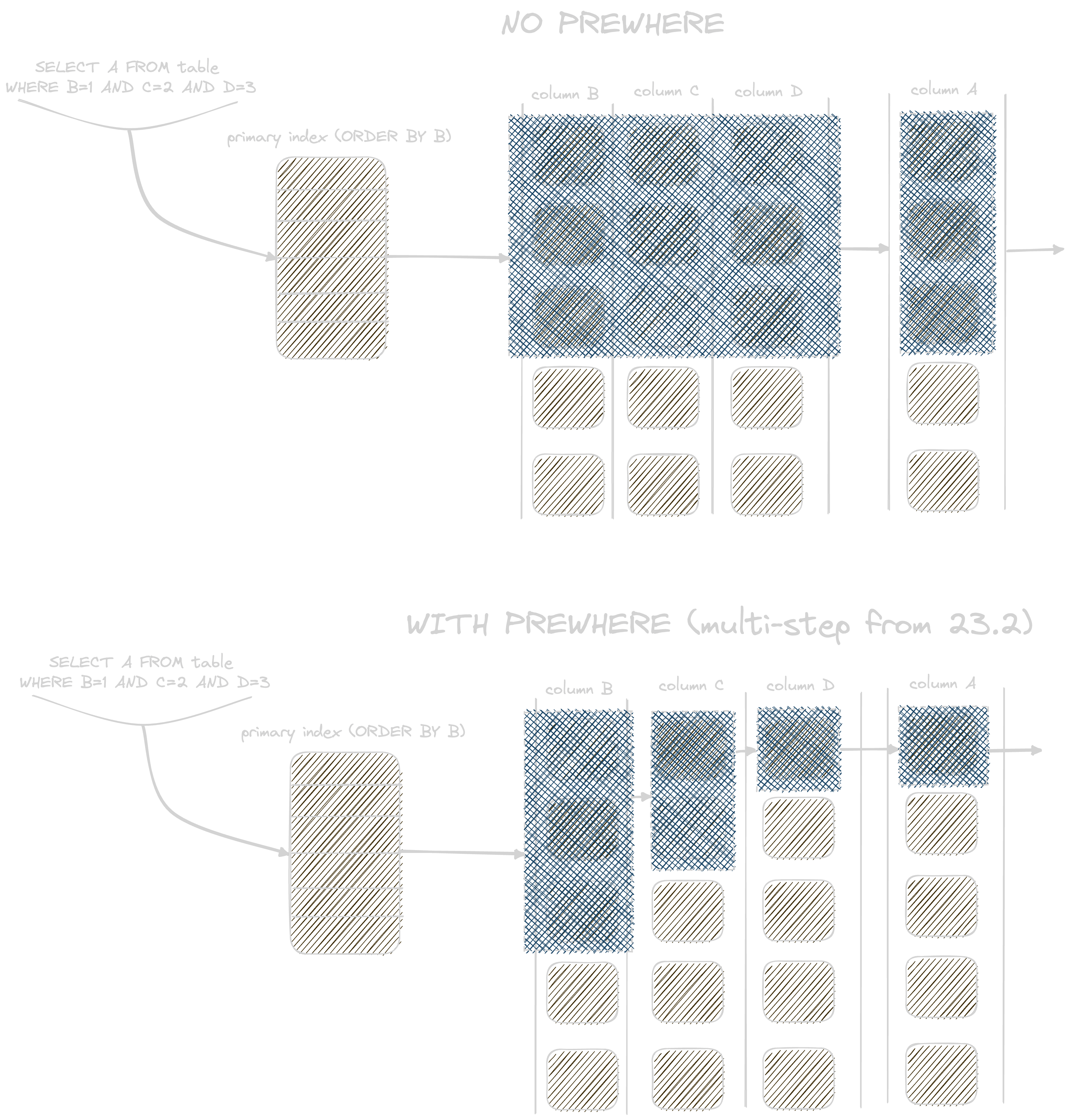
To emulate this optimization, users can rewrite queries to use sub queries. For example, consider the following query which finds the average price for properties in London:
–establish correct answer in postgres
postgres=> SELECT avg(price)
FROM uk_price_paid WHERE town = 'LONDON';
avg
---------------------
474799.921480528985
(1 row)
SELECT avg(price)
FROM uk_price_paid
WHERE town = 'LONDON'
┌─────────avg(price)─┐
│ 474797.35553246835 │
└────────────────────┘
1 row in set. Elapsed: 0.033 sec. Processed 27.74 million rows, 39.93 MB (835.45 million rows/s., 1.20 GB/s.)
EXPLAIN SYNTAX
SELECT avg(price)
FROM uk_price_paid
WHERE town = 'LONDON'
┌─explain──────────────────┐
│ SELECT avg(price) │
│ FROM uk_price_paid │
│ PREWHERE town = 'LONDON' │
└──────────────────────────┘
3 rows in set. Elapsed: 0.002 sec.
While this result is not correct without FINAL, we can see the PREWHERE optimization is applied to help to achieve an execution time of 0.075s. Using FINAL below returns the correct answer but reduces performance by over 20 times.
SELECT avg(price)
FROM uk_price_paid
FINAL
WHERE town = 'LONDON'
┌───────avg(price)─┐
│ 474799.921480529 │
└──────────────────┘
1 row in set. Elapsed: 0.725 sec. Processed 29.65 million rows, 1.41 GB (40.88 million rows/s., 1.94 GB/s.)
EXPLAIN SYNTAX
SELECT avg(price)
FROM uk_price_paid
FINAL
WHERE town = 'LONDON'
┌─explain───────────────┐
│ SELECT avg(price) │
│ FROM uk_price_paid │
│ FINAL │
│ WHERE town = 'LONDON' │
└───────────────────────┘
4 rows in set. Elapsed: 0.004 sec.
We can partially emulate the PREWHERE by returning primary keys in a subquery and only using FINAL on the outer query as shown. This doesn’t achieve the same performance as the earlier (inaccurate) query but provides some improvement for the increased complexity:
SELECT avg(price)
FROM uk_price_paid
FINAL
WHERE ((postcode1, postcode2) IN (
SELECT
postcode1,
postcode2
FROM uk_price_paid
WHERE town = 'LONDON'
GROUP BY
postcode1,
postcode2
)) AND (town = 'LONDON')
┌───────avg(price)─┐
│ 474799.921480529 │
└──────────────────┘
1 row in set. Elapsed: 0.287 sec. Processed 31.55 million rows, 230.30 MB (109.88 million rows/s., 802.08 MB/s.)
This workaround is most effective when the inner query returns a small subset of the primary key values.
Exploiting partitions
Merging of data in ClickHouse occurs at a partition level. When using ReplacingMergeTree,
we recommend users partition their table according to best practices, provided users can ensure this** partitioning key does not change for a row**. This will ensure updates pertaining to the same row will be sent to the same ClickHouse partition.
Assuming this is the case, users can use the setting do_not_merge_across_partitions_select_final=1 to improve FINAL query performance. This setting causes partitions to be merged and processed independently when using = FINAL. Consider the following table, where we partition the data by year and compute the average price across several partitions.
CREATE TABLE default.uk_price_paid_year
(
`id` UInt64,
`price` UInt32,
`date` Date,
`postcode1` LowCardinality(String),
`postcode2` LowCardinality(String),
`type` Enum8('other' = 0, 'terraced' = 1, 'semi-detached' = 2, 'detached' = 3, 'flat' = 4),
`is_new` UInt8,
`duration` Enum8('unknown' = 0, 'freehold' = 1, 'leasehold' = 2),
`addr1` String,
`addr2` String,
`street` LowCardinality(String),
`locality` LowCardinality(String),
`town` LowCardinality(String),
`district` LowCardinality(String),
`county` LowCardinality(String),
`version` UInt64,
`deleted` UInt8
)
ENGINE = ReplacingMergeTree( version, deleted) PRIMARY KEY (postcode1, postcode2, addr1, addr2)
ORDER BY (postcode1, postcode2, addr1, addr2, id) PARTITION BY toYear(date)
INSERT INTO default.uk_price_paid_year SELECT * FROM default.uk_price_paid
——query on original table
SELECT avg(price)
FROM uk_price_paid
FINAL
WHERE (toYear(date) >= 1990) AND (toYear(date) <= 2000)
┌────────avg(price)─┐
│ 85861.88784270117 │
└───────────────────┘
1 row in set. Elapsed: 0.702 sec. Processed 29.65 million rows, 1.44 GB (42.23 million rows/s., 2.05 GB/s.)
-– query on partitioned table
SELECT avg(price)
FROM uk_price_paid_year
FINAL
WHERE (toYear(date) >= 1990) AND (toYear(date) <= 2000)
┌────────avg(price)─┐
│ 85861.88784270117 │
└───────────────────┘
1 row in set. Elapsed: 0.492 sec. Processed 9.27 million rows, 443.09 MB (18.83 million rows/s., 900.24 MB/s.)
-— performance with do_not_merge_across_partitions_select_final = 1
SET do_not_merge_across_partitions_select_final = 1
SELECT avg(price)
FROM uk_price_paid_year
FINAL
WHERE (toYear(date) >= 1990) AND (toYear(date) <= 2000)
┌────────avg(price)─┐
│ 85861.88784270117 │
└───────────────────┘
1 row in set. Elapsed: 0.230 sec. Processed 7.62 million rows, 364.26 MB (33.12 million rows/s., 1.58 GB/s.)
As shown above, performance is improved by partitioning since our query targets 10 partitions and reduces the data required for reading. It is further improved by limiting query time deduplication to the partitions independently.
Conclusion
In this blog post we have explored the building blocks of a pull-based CDC pipeline for moving data between Postgres to ClickHouse using Debezium. This includes an introduction to how to track changes in Postgres, Debezium, and the ReplacingMergeTree. These concepts can be combined to produce the following pipeline.
In the next post in this series, we will build a working pipeline for a test dataset, highlighting important configuration options to ensure the respective components interact correctly. Stay tuned!


