At ClickHouse, we see our mission as providing our customers and users with a blazing-fast cloud analytical database that can be used for internal and customer-facing analytics. ClickHouse Cloud allows our customers to store and process virtually unlimited amounts of data, which helps them make data-driven decisions. Making decisions based on facts, and not on assumptions, is crucial for most successful businesses today.
Of course, we follow the same approach inside our team. Developing and operating our cloud database product generates a massive amount of data that can be used for capacity planning, pricing, understanding our customers' needs better, and financial reporting. Tens of data sources, hundreds of terabytes, and around one hundred BI and ad-hoc users… And guess what - we are using ClickHouse Cloud for handling this :)
In this post, I will share how our internal Data Warehouse (DWH) is built, the stack we use, and how our DWH will be evolving in the next few months.
Requirements and data sources
We launched ClickHouse Cloud in Private Preview in May 2022, and at the same time, we realized that we want to understand our customers better: how they use our service, which struggles they have, how we can help them, and how we can make our pricing affordable and reasonable for them. For this, we needed to collect and process data from multiple internal data sources: the Data Plane, which is responsible for running customer’s database pods, the Control Plane, which is responsible for customer-facing UI and database operations, and AWS Billing, which gives us exact costs for running customers’ workloads.
There was a short period of time when our VP Product, Tanya Bragin, did a manual analysis of our customers' workloads in Excel using lookups on a daily basis. It was a shame for me as an ex DWH architect that she had to struggle like this, so as a result the first concept of the internal DWH was born.
In designing the system, we had a number of critical tasks that we aimed to support our internal stakeholders, a handful of which are listed below.
| Internal team | Tasks |
|---|---|
| Product team | Tracking conversion and retention rates, feature usage, services size, usage and finding most common problems. Doing deep ad-hoc analysis. |
| Operations team | Tracking approximate revenue and providing access to some Salesforce data in read-only mode to most of the company |
| Sales team | Viewing particular customer setup and usage: how many services, how much data, common problems, etc. |
| Engineering team | Tuning our autoscaler, tracking query error rate and DB features usage |
| Support team | Viewing a particular customer setup: services, usage, amount of data, etc |
| Marketing team | Tracking top-of-funnel conversion rates, customer acquisition cost and other marketing metrics |
| Costs saving team | Analyzing our CSP costs and proactively optimizing our CSP commitments |
| CI-CD team | Tracking CI-CD costs |
Note: in our internal data warehouse we don’t collect, store, or process any part of our customer’s data (most of which is encrypted) such as the table data, query text, network data, etc. For example, for query analysis, we only collect a list of the used functions, query runtime, memory used and some other meta information. We never collect the query data or query text.
To accomplish this, we laid out a plan to ingest data from tens of sources, including the following.
| Data source | Type and size | Data |
|---|---|---|
| Control Plane | DocumentDB ~5 collections ~500 Mb per hour | Database services meta information: type, size, CSP region, state, financial plan, scaling settings, etc. |
| Data Plane | ClickHouse Cloud ~5 tables ~15 Gb per hour | Database system information: metrics stats, query stats, table stats, pod allocation, etc. |
| AWS CUR | S3 bucket 1 table ~1 Gb per hour | Our costs and usage for AWS infrastructure that runs our service |
| GCP Billing | BigQuery 1 table ~500 Mb per hour | Our costs and usage for GCP infrastructure that runs our service |
| Salesforce (CRM) | Custom ~30 tables ~1 Gb per hour | Information about customers' accounts, usage plans, subscriptions, discounts, regions, leads and support issues |
| M3ter (metering software) | Custom API 2 APIs ~500 Mb per hour | Accurate usage information and bills |
| Galaxy | ClickHouse Cloud 1 table | Galaxy is our event-based observability and monitoring system for our Control Plane / UI Layer |
| Segment | S3 Bucket 1 Table | Some additional marketing data |
| Marketo | Custom | Sent email meta information |
| AWS Public prices | Custom API 3 tables | Prices for every AWS SKU in every region |
| GCP Prices | CSV files | Prices for every GCP SKU in every region |
- At our current stage, one-hour granularity in our data is enough. Meaning, we can collect and store aggregates for every hour.
- For now, we don’t need to use the CDC (or “change data capture”) approach, as it makes the DWH infrastructure much more expensive. Traditional direct load / ETL should satisfy our needs. If these data sources are subject to updates, we can perform a complete data reload.
- As we have a great scalable and fast database, we don’t need to perform ETL transformations outside of the database. Rather, we instead use ClickHouse directly to perform transformations using SQL. This works great.
- At ClickHouse, we are open-source by our nature, so we want all our stack to have only open source components. We also love to contribute.
- As we have very different types of data sources, we will need multiple tools and approaches for extracting data from these sources. At the same time, we need a standardized intermediate storage.
However, one of our other initial assumptions proved incorrect. We had assumed that, because our data structure was not so complex, it would be enough for us to have only two logical layers in the DWH - the raw layer and a “data mart” layer. This was a mistake. In reality, we needed a third intermediate layer storing internal business entities. We will explain it below.
Architecture
As a result, we came up with the following architecture:
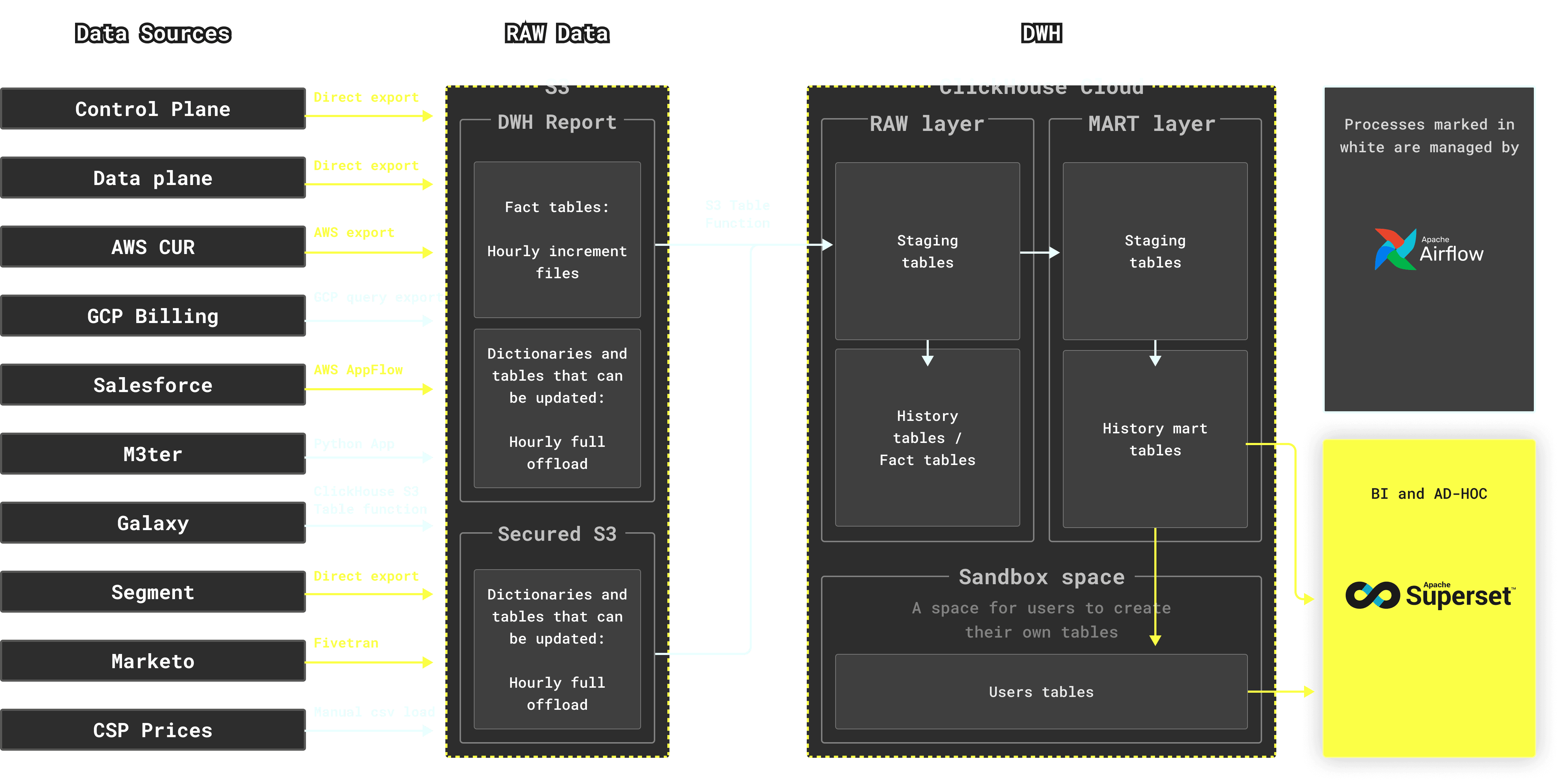
-
From a high-level, our stack can be described as:
- ClickHouse Cloud as the main database
- Airflow as a scheduler (an open source scheduling tool)
- AWS S3 as an intermediate storage for RAW data
- Superset as internal BI & AD-HOC tool
-
We use different tools and approaches to capture data from data sources to multiple S3 buckets:
- For Control Plane, Data Plane, Segment and AWS CUR, we use the data source’s native functionality to export data
- For GCP billing, we use BigQuery export queries to export data to GCS, from where it can be ingested by the ClickHouse S3 table function
- For Salesforce, we use AWS AppFlow
- For capturing data from M3ter, we wrote our own application. Originally it was written in Kotlin, later we migrated it to Python
- For Galaxy (which is presented by a ClickHouse Cloud cluster), we use the ClickHouse S3 table function to export data to S3
- For Marketo, we use Fivetran
- Finally, as AWS and GCP prices change very rarely, we decided not to automate its load but created some scripts that help us manually update CSP prices if needed
-
For large fact tables, we collect hourly increments. For dictionaries and tables that can not only receive new rows, but also updates, we use the “replace” approach (i.e. we download the entire table every hour).
-
Once hourly data is collected in the S3 bucket, we use the ClickHouse s3 table function to import data to the ClickHouse database. The S3 table function scales across replicas and works great on large amounts of data.
-
From the S3 bucket, data is inserted into the RAW layer in the database. This layer has the same table structure as the sources.
-
After a series of transformations run by Airflow (including joins), data from raw tables is inserted into the MART tables - these tables represent business entities and satisfy the needs of our internal stakeholders.
When performing transformations, many temporary tables are used. In fact, most of the transformed results are at first written to a staging table, and only then are they inserted into the target table. Though such an approach introduces some complexity, it also gives us the required flexibility of reusing the increment data. This allows a single increment part to be used multiple times without recalculating it or rescanning the target table. Staging tables have unique names for every Airflow DAG (Directed acyclic graphs) run.
-
Finally, the Superset BI tool allows our internal users to query MART tables as well as build charts and dashboards:
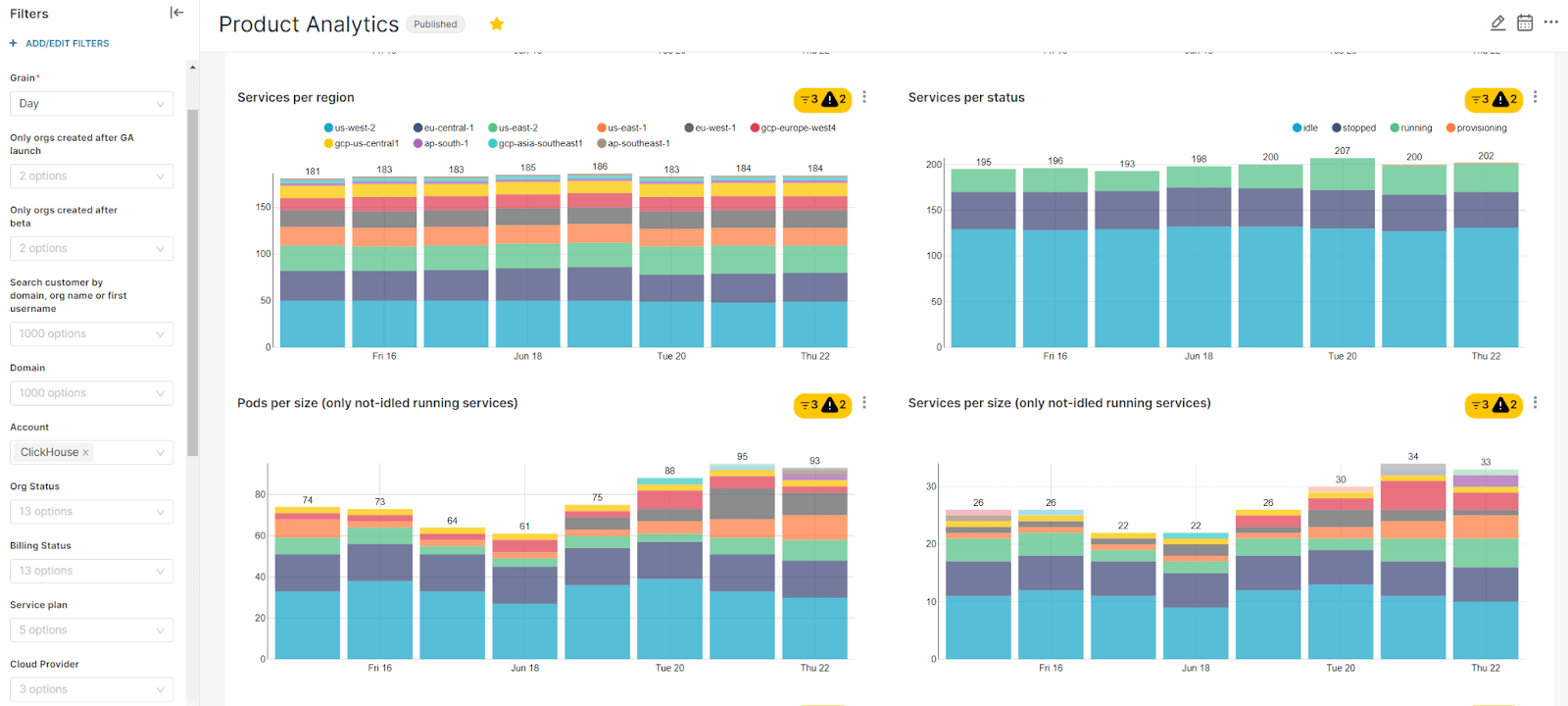 Example Superset dashboard. Note: for illustration purposes, sample data with fake numbers is presented.
Example Superset dashboard. Note: for illustration purposes, sample data with fake numbers is presented.
Idempotency
Most of the tables that we use in ClickHouse use ReplicatedReplacingMergeTree engines. This engine allows us not to care about duplicates in tables - records with the same key will be squashed and only the last record retained. This also means that we can insert the data for one particular hour as many times as it is required - only one last version of every row will survive. We also use ClickHouse’s feature “FINAL” when the table is used in further transformations to achieve consistency, so, for example, the sum() function doesn’t calculate a row twice.
When combined with Airflow jobs/DAGs that are tolerant to running multiple times for the same period, our pipeline is fully idempotent and can be safely re-executed without resulting in duplicates. More details on internal Airflow design will be given below.
Consistency
By default, ClickHouse provides eventual consistency. This means that if you successfully run a insert query it doesn’t guarantee that the new data is in all ClickHouse replicas. This is sufficient for real time analytics, but unacceptable for the DWH scenario. Imagine, for instance, that you insert data into a staging table. The insert successfully completes and your ELT process starts to execute the next query that reads from the staging table… and you get only partial data.
However, ClickHouse offers a different mode for use cases where consistency is more important than instant availability of inserted data on the first node. To guarantee that the insert query does not return “success” until all replicas have the data, we run all insert queries with a setting insert_quorum=3 (we have three nodes in our cluster). We don’t use the “auto” setting because when one node goes down (for example, when a ClickHouse upgrade is performed), it will still be possible for the two remaining nodes to accept inserts. Once the restarted node is available, there can be missing inserted data in this node for some time. So for us it is better to get an error (Number of alive replicas (2) is less than requested quorum (3/3).. (TOO_FEW_LIVE_REPLICAS) when inserting data in less than three replicas. As restarts due to upgrades are quite fast, queries are usually successful when Airflow retries after an error.
Of course, such an approach doesn’t guarantee that uncommitted parts from previous failed inserts are not visible for a query, but this is not a problem as we support idempotency as described in the previous part. Another solution would be to run all ELT processes using only one replica, but this can limit performance.
Internal infrastructure design
Given our scale, we need our DWH infrastructure to be simple, easy to operate and easy to scale. After running an internal PoC directly on AWS EC2, we migrated all our infrastructure components to Docker.
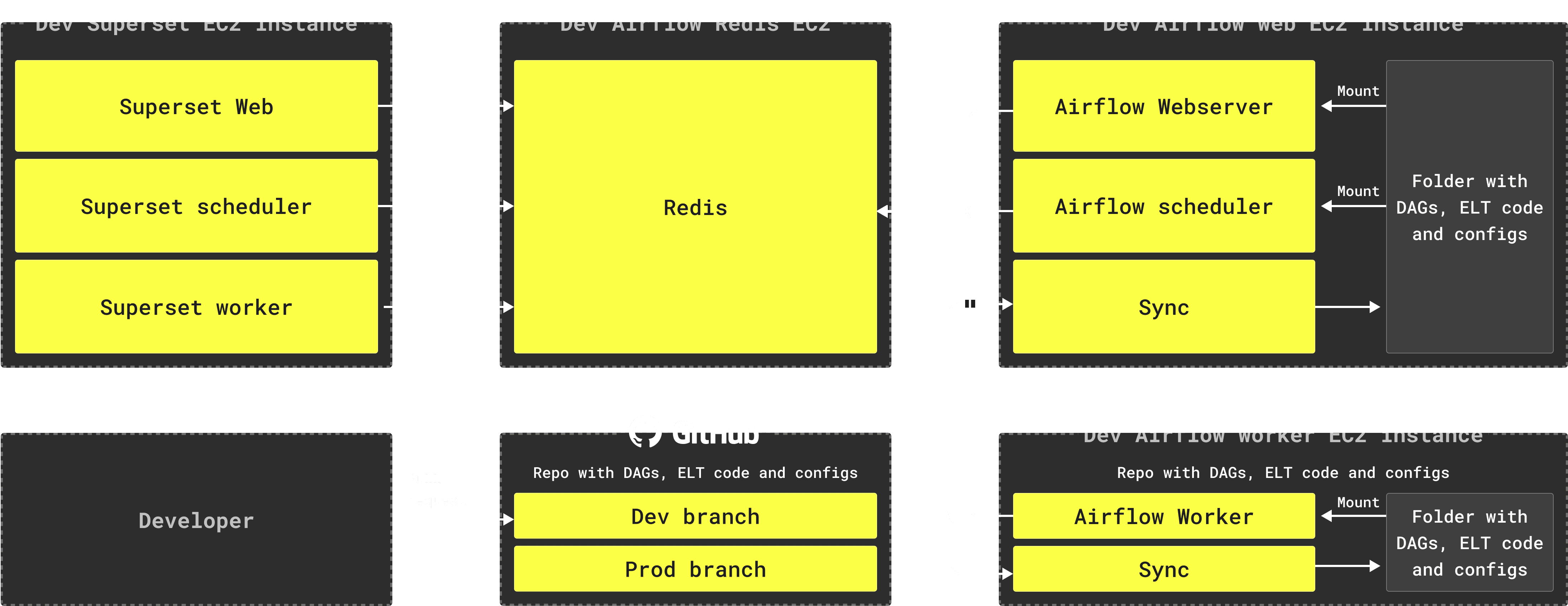
- We have separate machines for the Airflow web server, Airflow worker, and Superset. All components are packed in Docker containers
- On Airflow machines, we additionally run a container every 5 seconds that synchronizes the repository containing our DAGs code, ELT queries, and some configuration files with a folder located on the machines
- We use the Superset dashboards and alerts features, so we have a scheduler and worker containers for Superset
- All Airflow and Superset components are synchronized through a Redis instance that runs on a separate machine. Redis stores the execution state of job runs and worker code for Airflow, cached query results for Superset and some other service information
- We use AWS RDS for PostgreSQL as an internal database for Airflow and Superset
- We have two environments running independently with their own ClickHouse Cloud instances, Airflow and Superset installations in different regions
- Though one environment is named Preprod, and the other one is Prod, we keep Preprod consistent so we are be able to switch if Prod is unavailable
Such a setup allows us to make releases safely and easily:
- Developer creates a branch from a dev or production branch
- Developer makes changes
- Developer creates a PR to the Preprod branch
- Once the PR is reviewed and approved, changes go to the Preprod Airflow instance, where they are tested
- Once the changes are ready to be released to prod, a PR from Preprod to Prod branch is performed
Airflow internal design
Initially, we were thinking about creating a sophisticated DAG system with many dependencies. Unfortunately, none of the existing options of DAG dependency mechanics can work with the desired architecture (which is quite a common problem in Airflow):
- Airflow does not allow dataset names to change across executions. Newly introduced datasets therefore can’t use temporary names. If we use a static dataset name the downstream DAG will be run only once for the last increment.
- Triggers can work for us, but using triggers will add too much complexity to our setup. Having 10-20 DAGs with triggers, looks like a dependency nightmare from an operating perspective.
We thus ended up with the following structure:
- Separate DAGs for loading data from data source to S3 (for example, M3ter -> S3)
- A single huge main DAG that does all the transformations when data is delivered to S3
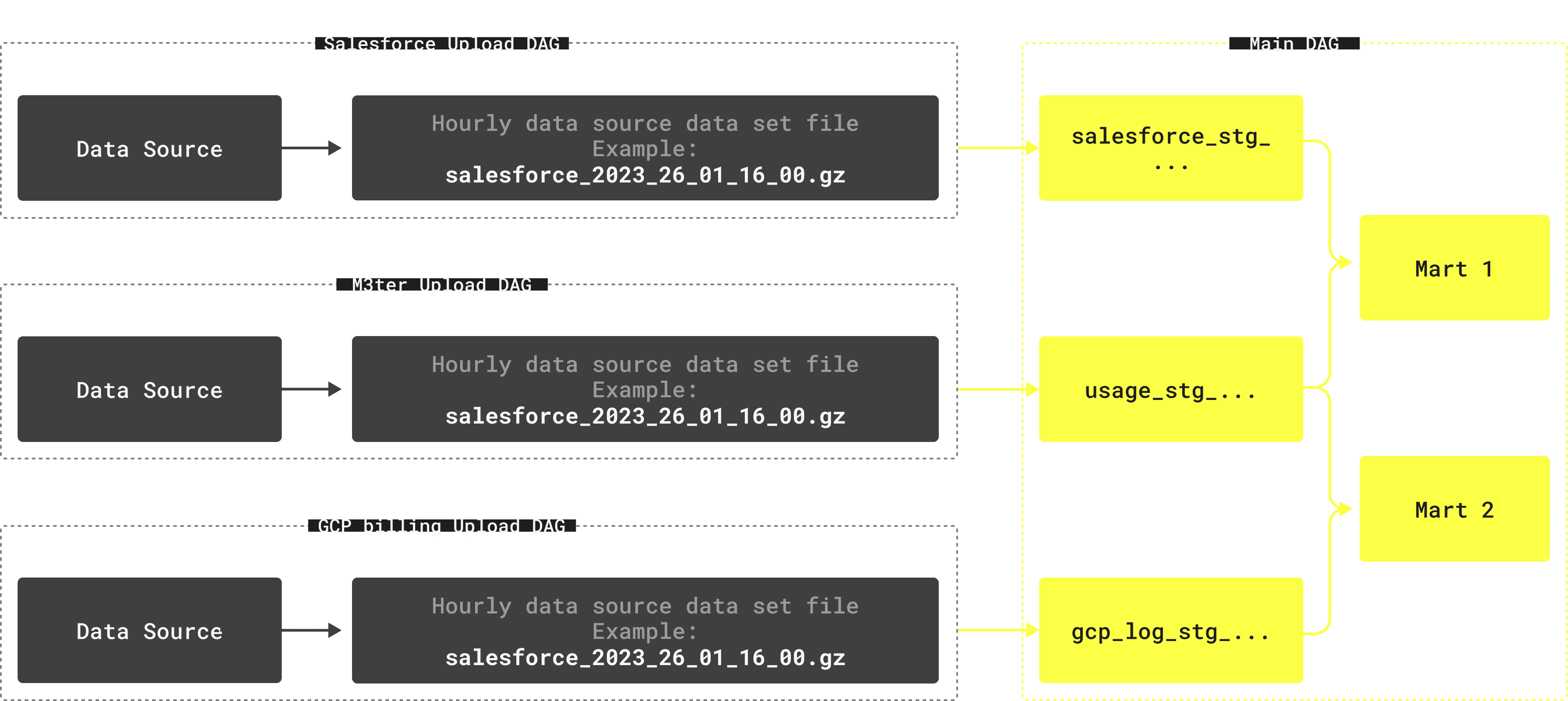
The main advantage of such an approach is that it combines both having all required dependencies clearly listed in the main DAG’s tasks, and the ability to build entities not connected to a failed dataset.
Security
As our internal DWH system stores sensitive data, including PII and financial information, security must be the foundation of our architecture. For this, we have implemented some basic rules and a set of frameworks on how we operate the DWH.
General rules
- Different data must be accessible by different users according to the company’s role model, and it should be done automatically
- Separating permissions should be done on the database level (not on the BI side!)
- Network access restrictions should be presented on all levels (from using Okta for the BI tool to IP filtering)
Implementation
We use Google groups to control internal user permissions. This allows us to use existing internal company groups, and also allows group owners (who can be presented by a non-technical person that doesn't care about SQL) to control access to different data. Groups can be nested. For example:
For matching Google groups with exact permissions, we use a system table that connects the:
- Google group name
- Database name
- Table name
- Array of columns
- Filter (for example, “where organization=’clickhouse’”)
- Access type (SELECT, INSERT)
We also have a script that does the following:
- Gets a recursive list of groups and users
- Creates (actually, replaces) these users in the database with a unique password
- Creates roles corresponding to Google groups
- Assigns roles to users
- Grants permissions to roles according to permission table with “WITH REPLACE OPTION” clause - this will remove all other grants that could be done manually for some reason
On the Superset side, we use the DB_CONNECTION_MUTATOR function to substitute the database username with the Superset user when a query is sent to the DB. We also have Google Oauth enabled in Superset. That means, in the DB_CONNECTION_MUTATOR we have everything we need to make Superset connect with the desired username and password:
def DB_CONNECTION_MUTATOR(uri, params, username, security_manager, source):
# Only enable mutator on clickhouse cloud endpoints
if not uri.host.lower().endswith("clickhouse.cloud"):
return uri, params
user = security_manager.find_user(username=username)
generated_username = str(user.email).split('@')[0] + '--' + str(user.username)
uri.username = generated_username
# Password generation logic - hidden in this example
uri.password = ...
return uri, params
The above means that Superset uses a unique database username for every user, with a unique set of permissions that are controlled by Google groups.
GDPR Compliance
ClickHouse Cloud users can ask us to delete all their personal data including name, email and other information. Of course, in this case we also delete this information from the DWH. The coolest thing here is that we don’t need to run any updates or deletes in ClickHouse tables. Because our engine leaves only one last record for every key value, all we need to do is to insert a new version of row with deleted users data. It will take a few hours for old rows to disappear, but GDPR standards give you from 3 to 30 days for data removal based on the scenario. So the full algorithm is:
- Find a special flag in one of the source system that this ID should be masked/deleted
- Select all records from the table with this ID
- Mask required fields
- Insert the data back to the table
- Run “optimize table … final” command to be sure old records are deleted from disk
- When a new hourly increment is coming we perform a join to the list of deleted IDs. This means if for some reason user’s PII information has not been fully removed yet, we will automatically mask this data
Improvements and plans for future
Though in general we are satisfied with our DWH, there are some things that we plan to change in the upcoming months:
Third logical layer
The idea of having only two logical layers, unfortunately, doesn’t work. We found that for calculating really complex metrics that can be backfilled and that need data from 5+ data sources, we have to create dependencies between different marts. Sometimes this even involves recursive dependencies. To solve this, we need to introduce an intermediate layer called the Detail Data Store, or DDS. It will store some internal business entities like account, organization, service, etc. This layer will not be available for end users, but it will help us to remove dependencies between marts.
DBT
Airflow is a good scheduler, but we need a tool that will take care of many other things: reloading data marts completely if needed, QA, data describing and documentation, and others. For that, we plan to integrate Airflow with DBT. As we run all our data infrastructure in Docker containers, it is quite easy to create a separate DBT container for our needs that will be triggered by Airflow DAGs.
Naming conventions
Though from the beginning we knew that we must follow some rules in how we name tables, fields and charts, we didn’t invest too many resources in this. As a result, we now have quite confusing namings that don’t allow users to understand the purpose of a particular table or field. We need to make it clearer.
Resources
ClickHouse is a relatively young company, so our DWH team is relatively small and has only 3 members:
- Data Engineer - builds and maintains the infrastructure
- Product Analyst - helps users with getting insights, building charts and understanding the data
- Team Lead - spends only ~30% time on DWH tasks
As for the infrastructure, we use two environments with separate ClickHouse Cloud services. Each service has 3 nodes (aka replicas, but all replicas are accepting queries). Memory usage for our ClickHouse services is ~200 Gb. While we don’t pay for these services as we are part of ClickHouse Cloud team, we researched competitors pricing and performance and believe that another cloud analytical database would be much more expensive in our case.
In addition, our infrastructure includes 8 EC2 machines and an S3 bucket with raw data. In total, these services cost about ~$1,500 per month.
Overall results
Our DWH has been operating for more than one year. We have >70 monthly active users, hundreds of dashboards, and thousands of charts. Altogether, users run ~40,000 queries per day. This chart shows the number of queries per day, and the breakdown is per user. System and ELT users excluded:
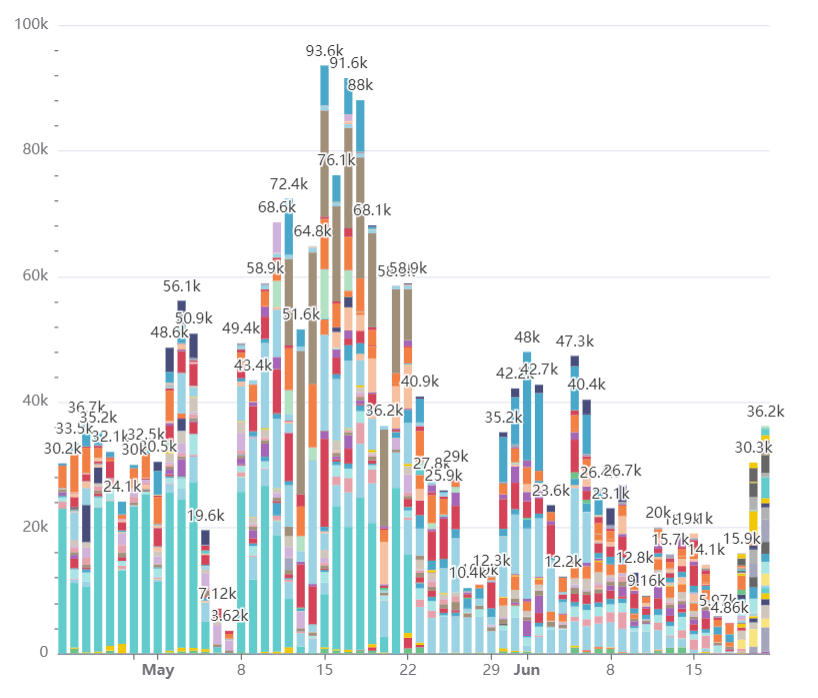
Yep, our users work on weekends, too
We store ~115 Tb of uncompressed data in ~150 tables, but because of ClickHouse’s efficient compression the actual stored data is only ~13 Tb.
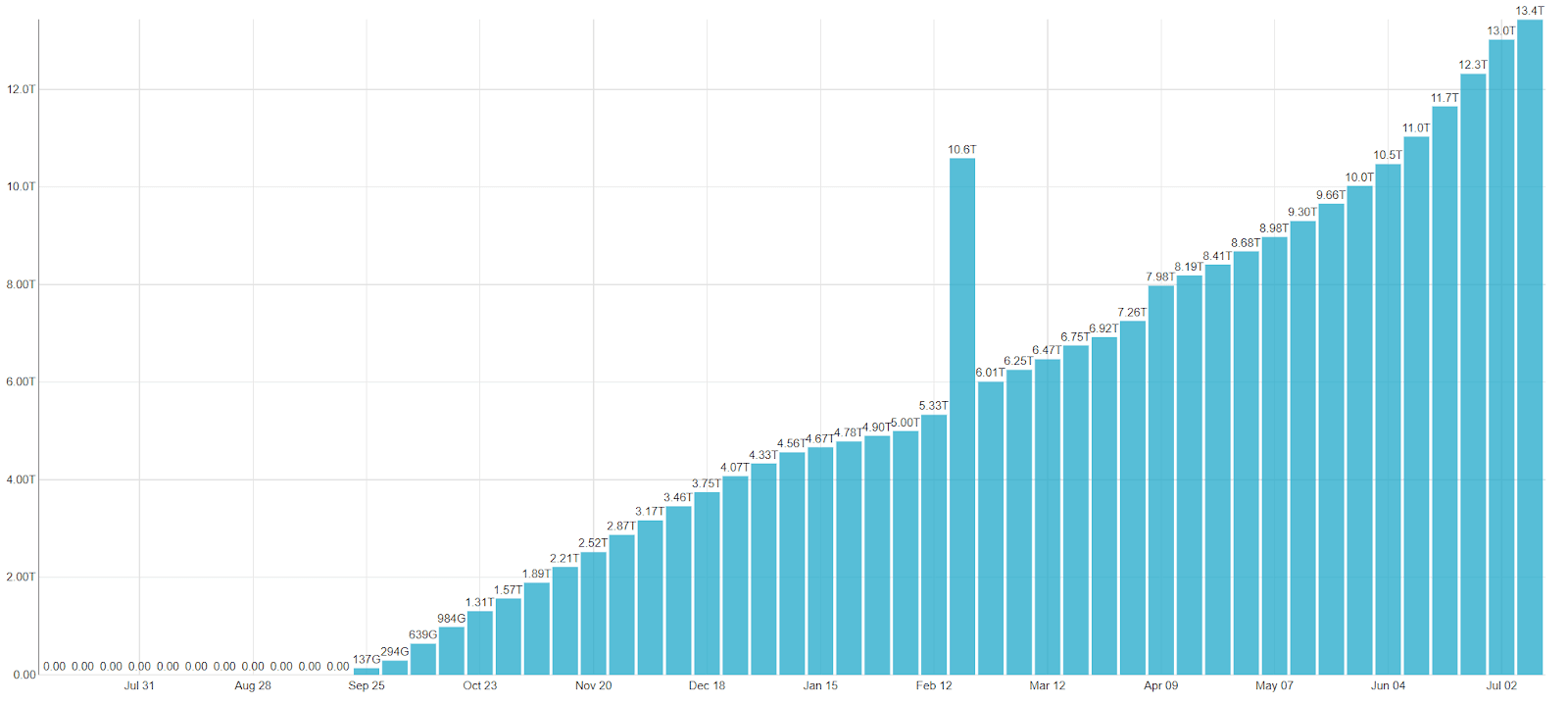
Week over week growth of the amount of data in our DWH. February spike represents an internal experiment that needed all data to be duplicated.
Summary
In one year we have deployed a DWH based on open-source technology that delivers an experience our users love. While our DWH makes it easy to work with data, we also see a lot of improvements and changes that we need to make to move forward. We believe that our usage of ClickHouse Cloud proves that it can be used to build a robust DWH.


