Что такое ClickHouse
ClickHouse — столбцовая система управления базами данных (СУБД) для онлайн-обработки аналитических запросов (OLAP).
В обычной, «строковой» СУБД, данные хранятся в таком порядке:
| Строка | WatchID | JavaEnable | Title | GoodEvent | EventTime |
|---|---|---|---|---|---|
| #0 | 89354350662 | 1 | Investor Relations | 1 | 2016-05-18 05:19:20 |
| #1 | 90329509958 | 0 | Contact us | 1 | 2016-05-18 08:10:20 |
| #2 | 89953706054 | 1 | Mission | 1 | 2016-05-18 07:38:00 |
| #N | … | … | … | … | … |
То есть, значения, относящиеся к одной строке, физически хранятся рядом.
Примеры строковых СУБД: MySQL, PostgreSQL, MS SQL Server. {: .grey }
В столбцовых СУБД данные хранятся в таком порядке:
| Строка: | #0 | #1 | #2 | #N |
|---|---|---|---|---|
| WatchID: | 89354350662 | 90329509958 | 89953706054 | … |
| JavaEnable: | 1 | 0 | 1 | … |
| Title: | Investor Relations | Contact us | Mission | … |
| GoodEvent: | 1 | 1 | 1 | … |
| EventTime: | 2016-05-18 05:19:20 | 2016-05-18 08:10:20 | 2016-05-18 07:38:00 | … |
В примерах изображён только порядок расположения данных. То есть значения из разных столбцов хранятся отдельно, а данные одного столбца — вместе.
Примеры столбцовых СУБД: Vertica, Paraccel (Actian Matrix, Amazon Redshift), Sybase IQ, Exasol, Infobright, InfiniDB, MonetDB (VectorWise, Actian Vector), LucidDB, SAP HANA и прочий треш, Google Dremel, Google PowerDrill, Druid, kdb+. {: .grey }
Разный порядок хранения данных лучше подходит для разных сценариев работы. Сценарий работы с данными — это то, какие производятся запросы, как часто и в каком соотношении; сколько читается данных на запросы каждого вида — строк, столбцов, байтов; как соотносятся чтения и обновления данных; какой рабочий размер данных и насколько локально он используется; используются ли транзакции и с какой изолированностью; какие требования к дублированию данных и логической целостности; требования к задержкам на выполнение и пропускной способности запросов каждого вида и т. п.
Чем больше нагрузка на систему, тем более важной становится специализация под сценарий работы, и тем более конкретной становится эта специализация. Не существует системы, одинаково хорошо подходящей под существенно различные сценарии работы. Если система подходит под широкое множество сценариев работы, то при достаточно большой нагрузке система будет справляться со всеми сценариями работы плохо, или справляться хорошо только с одним из сценариев работы.
Ключевые особенности OLAP-сценария работы
- подавляющее большинство запросов — на чтение;
- данные обновляются достаточно большими пачками (> 1000 строк), а не по одной строке, или не обновляются вообще;
- данные добавляются в БД, но не изменяются;
- при чтении «вынимается» достаточно большое количество строк из БД, но только небольшое подмножество столбцов;
- таблицы являются «широкими», то есть содержат большое количество столбцов;
- запросы идут сравнительно редко (обычно не более сотни в секунду на сервер);
- при выполнении простых запросов, допустимы задержки в районе 50 мс;
- значения в столбцах достаточно мелкие — числа и небольшие строки (например, 60 байт на URL);
- требуется высокая пропускная способность при обработке одного запроса (до миллиардов строк в секунду на один сервер);
- транзакции отсутствуют;
- низкие требования к согласованности данных;
- в запросе одна большая таблица, все остальные таблицы из запроса — маленькие;
- результат выполнения запроса существенно меньше исходных данных — то есть данные фильтруются или агрегируются; результат выполнения помещается в оперативную память одного сервера.
Легко видеть, что OLAP-сценарий работы существенно отличается от других распространённых сценариев работы (например, OLTP или Key-Value сценариев работы). Таким образом, не имеет никакого смысла пытаться использовать OLTP-системы или системы класса «ключ — значение» для обработки аналитических запросов, если вы хотите получить приличную производительность («выше плинтуса»). Например, если вы попытаетесь использовать для аналитики MongoDB или Redis — вы получите анекдотически низкую производительность по сравнению с OLAP-СУБД.
Причины, по которым столбцовые СУБД лучше подходят для OLAP-сценария
Столбцовые СУБД лучше (от 100 раз по скорости обработки большинства запросов) подходят для OLAP-сценария работы. Причины в деталях будут разъяснены ниже, а сам факт проще продемонстрировать визуально:
Строковые СУБД
Столбцовые СУБД
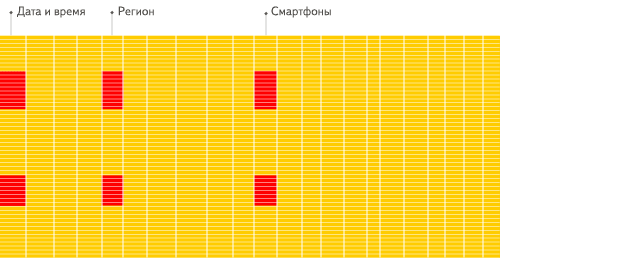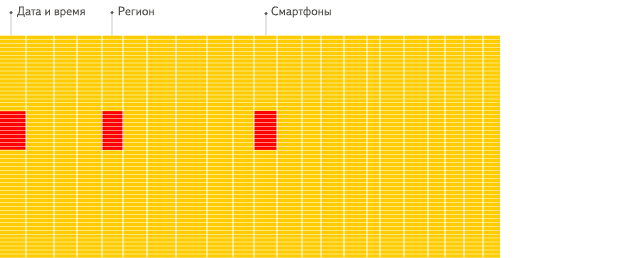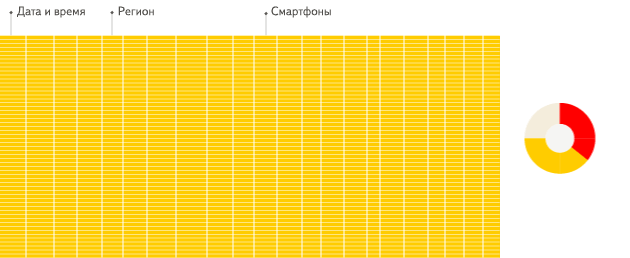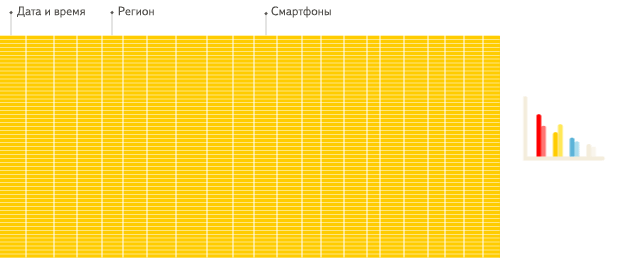
Видите разницу?
По вводу-выводу
- Для выполнения аналитического запроса требуется прочитать небольшое количество столбцов таблицы. В столбцовой БД для этого можно читать только нужные данные. Например, если вам требуется только 5 столбцов из 100, то следует рассчитывать на 20-кратное уменьшение ввода-вывода.
- Так как данные читаются пачками, то их проще сжимать. Данные, лежащие по столбцам, также лучше сжимаются. За счёт этого, дополнительно уменьшается объём ввода-вывода.
- За счёт уменьшения ввода-вывода больше данных влезает в системный кэш.
Например, для запроса «посчитать количество записей для каждой рекламной системы» требуется прочитать один столбец «идентификатор рекламной системы», который занимает 1 байт в несжатом виде. Если большинство переходов было не с рекламных систем, то можно рассчитывать хотя бы на десятикратное сжатие этого столбца. При использовании быстрого алгоритма сжатия возможно разжатие данных со скоростью более нескольких гигабайт несжатых данных в секунду. То есть такой запрос может выполняться со скоростью около нескольких миллиардов строк в секунду на одном сервере. На практике такая скорость действительно достигается.
По вычислениям
Так как для выполнения запроса надо обработать достаточно большое количество строк, становится актуальным диспетчеризовывать все операции не для отдельных строк, а для целых векторов, или реализовать движок выполнения запроса так, чтобы издержки на диспетчеризацию были примерно нулевыми. Если этого не делать, то при любой не слишком плохой дисковой подсистеме, интерпретатор запроса неизбежно упрётся в CPU. Имеет смысл не только хранить данные по столбцам, но и обрабатывать их, по возможности, тоже по столбцам.
Есть два способа это сделать:
Векторный движок. Все операции пишутся не для отдельных значений, а для векторов. То есть, вызывать операции надо достаточно редко, и издержки на диспетчеризацию становятся пренебрежимо маленькими. Код операции содержит в себе хорошо оптимизированный внутренний цикл.
Кодогенерация. Для запроса генерируется код, в котором подставлены все косвенные вызовы.
В «обычных» СУБД этого не делается, так как не имеет смысла при выполнении простых запросов. Хотя есть исключения. Например, в MemSQL кодогенерация используется для уменьшения времени отклика при выполнении SQL-запросов. Для сравнения: в аналитических СУБД требуется оптимизация по пропускной способности (throughput, ГБ/с), а не времени отклика (latency, с).
Стоит заметить, что для эффективности по CPU требуется, чтобы язык запросов был декларативным (SQL, MDX) или хотя бы векторным (J, K, APL). То есть необходимо, чтобы запрос содержал циклы только в неявном виде, открывая возможности для оптимизации.