Blog

Engineering
Announcing the Fivetran Destination For ClickHouse Cloud
We’re delighted to announce the availability of the Fivetran destination for ClickHouse Cloud.
Ryadh Dahimene
Apr 25, 2024
- View All
- Engineering
- Customer stories
- Product
- Community
- Company and culture

Engineering
Announcing adsb.exposed - Interactive Visualization and Analytics on ADS-B Flight Data with ClickHouse

Customer stories
LangChain - Why we Choose ClickHouse to Power LangSmith

Customer stories
Didi Migrates from Elasticsearch to ClickHouse for a new Generation Log Storage System
Product
ClickPipes for Batch Data Loading: Introducing S3 and GCS Support

Community
April 2024 Newsletter
Engineering
Chaining Materialized Views in ClickHouse

Engineering
How to Scale K-Means Clustering with just ClickHouse SQL

Engineering
ClickHouse Release 24.3
Product
The new ClickHouse Cloud experience

Engineering
Training Machine Learning Models with ClickHouse and Featureform

Engineering
How we Built a 19 PiB Logging Platform with ClickHouse and Saved Millions
Community
March 2024 Newsletter

Engineering
Manage your ClickHouse Schema-as-Code using Atlas

Engineering
ClickHouse Release 24.2

Community
chDB joins the ClickHouse family

Engineering
ClickHouse and The One Trillion Row Challenge
Engineering
Building a Chatbot for Hacker News and Stack Overflow with LlamaIndex and ClickHouse
Community
February 2024 Newsletter

Customer stories
Streamkap: An out-of-the-box CDC solution for ClickHouse

Customer stories
How Grupo MasMovil Monitors Radio Access Networks with ClickHouse

Product
ClickHouse and the Machine Learning Data Layer
Engineering
ClickHouse Release 24.1

Engineering
Exploring Global Internet Speeds using Apache Iceberg and ClickHouse

Product
ClickHouse Grafana plugin 4.0 - Leveling up SQL Observability
Engineering
A Hybrid Query Execution Experiment
Customer stories
Better Analytics at Scale with Trackingplan and ClickHouse

Engineering
ClickHouse and The One Billion Row Challenge

Engineering
Powering Feature Stores with ClickHouse

Engineering
ClickHouse Release 23.12

Engineering
Monitoring Asynchronous Inserts

Engineering
ClickHouse Release 23.11

Engineering
Goldsky - A Gold Standard Architecture with ClickHouse and Redpanda

Product
Celebrating a Year of Growth

Engineering
Linear Regression Using ClickHouse Machine Learning Functions

Product
The State of SQL-based Observability

Engineering
ANN Vector Search with SQL-powered LSH & Random Projections

Engineering
SQL Dynamic Column Selection with ClickHouse
Engineering
Building a RAG pipeline for Google Analytics with ClickHouse and Amazon Bedrock

Engineering
Enhancing Google Analytics Data with ClickHouse

Engineering
Querying Pandas DataFrames with ClickHouse

Engineering
Cost-predictable logging at scale with ClickHouse, Grafana & WarpStream

Engineering
ClickHouse Release 23.10

Customer stories
RunReveal Is Building The Ridiculously Fast Security Data Platform On ClickHouse

Product
The Unbundling of the Cloud Data Warehouse

Engineering
Supercharging your large ClickHouse data loads - Making a large data load resilient

Engineering
Forecasting Using ClickHouse Machine Learning Functions

Product
Announcing GenAI powered query suggestions in ClickHouse Cloud

Engineering
ClickHouse Release 23.9

Engineering
Supercharging your large ClickHouse data loads - Tuning a large data load for speed

Engineering
Saving Millions of Dollars by Bin-Packing ClickHouse Pods in AWS EKS

Engineering
A MySQL Journey

Engineering
ClickHouse Cloud now Compatible with the MySQL Protocol

Engineering
CPU Dispatch in ClickHouse

Engineering
chDB - A Rocket Engine on a Bicycle

Engineering
ClickHouse Keeper: A ZooKeeper alternative written in C++

Product
ClickPipes is Now Generally Available

Product
ClickHouse Announces ClickPipes: A Continuous Data Ingestion Service for ClickHouse Cloud

Community
London Meetup Report: How Cloudflare Processes Hundreds of Millions of Rows per Second with ClickHouse

Engineering
Supercharging your large ClickHouse data loads - Performance and resource usage factors

Engineering
ClickHouse Release 23.8

Engineering
Using ClickHouse UDFs to integrate with OpenAI models

Engineering
Kafka, Latency, and You: Minimizing Latency with Kafka & ClickHouse

Engineering
Escape from Snowflake's Costs: Unlock Savings and Speed with ClickHouse Cloud for Real-Time Analytics

Engineering
ClickHouse vs Snowflake for Real-Time Analytics - Benchmarks and Cost Analysis

Engineering
ClickHouse vs Snowflake for Real-Time Analytics - Comparing and Migrating

Product
Welcome, chDB

Product
ClickHouse Release 23.7

Engineering
Analyzing Hugging Face datasets with ClickHouse

Customer stories
Ongage's Strategic Shift to ClickHouse for Real-time Email Marketing

Product
ClickHouse Cloud boosts performance with SharedMergeTree and Lightweight Updates


Community
SF Meetup Report: Helicone's Migration from Postgres to ClickHouse for Advanced LLM Monitoring

Engineering
Fuzzing collaboration with WINGFUZZ - Part 1
Engineering
Asynchronous Data Inserts in ClickHouse

Customer stories
Building a Unified Data Platform with ClickHouse
Community
Singapore Meetup Report: How ClickHouse Powers Ahrefs, the World's Most Active Web Crawler
Product
ClickHouse Newsletter July 2023: Seeing Clearly

Engineering
Real-time event streaming with ClickHouse, Confluent Cloud and ClickPipes

Engineering
How we built the Internal Data Warehouse at ClickHouse

Product
ClickPipes for Kafka - ClickHouse Cloud Managed Ingestion Service

Engineering
Using ClickHouse Cloud and Terraform for CI/CD
Community
NYC Meetup Report: Vantage's Journey from Redshift and Postgres to ClickHouse

Community
Learning ClickHouse - A Story about Community
Community
London Meetup Report: Scaling Analytics with PostHog and Introducing HouseWatch

Product
ClickHouse Release 23.6

Engineering
Choosing the Right Join Algorithm

Customer stories
Driving Sustainable Data Management with ClickHouse: Introducing Stash by Modeo

Customer stories
Boosting Game Performance: ExitLag's Quest for a Better Data Management System

Customer stories
Harnessing the Power of Materialized Views and ClickHouse for High-Performance Analytics at Inigo

Engineering
Real-time Event Streaming with ClickHouse, Kafka Connect and Confluent Cloud

Engineering
ClickHouse Release 23.5

Product
ClickHouse Cloud on Google Cloud Platform (GCP) is Generally Available

Company and culture
ClickHouse Cloud Expands Choice With Launch on Google Cloud Platform

Engineering
Change Data Capture (CDC) with PostgreSQL and ClickHouse - Part 2

Engineering
Change Data Capture (CDC) with PostgreSQL and ClickHouse - Part 1

Engineering
Building an Auto-Scaling Lambda based on Github's Workflow Job Queue

Engineering
SigNoz: Open Source Metrics, Traces and Logs in a single pane based natively on OpenTelemetry

Engineering
ClickHouse Joins Under the Hood - Direct Join

Product
ClickHouse Cloud Updates: GCP Beta, API Support, S3 IAM roles, and more

Engineering
Vector Search with ClickHouse - Part 2

Engineering
Vector Search with ClickHouse - Part 1

Product
Using the New ClickHouse Cloud API to Automate Deployments

Engineering
ClickHouse Joins Under the Hood - Full Sorting Merge Join, Partial Merge Join - MergingSortedTransform
Engineering
IP-based Geolocation in ClickHouse

Customer stories
OONI Powers its Measurement of Internet Censorship with ClickHouse
Engineering
Hash tables in ClickHouse and C++ Zero-cost Abstractions

Engineering
Adding Real Time Analytics to a Supabase Application With ClickHouse

Product
ClickHouse Cloud on GCP Available in Public Beta

Customer stories
Coinpaprika Aggregates Pricing Data Across Hundreds of Cryptocurrency Exchanges with ClickHouse

Engineering
Deploying ClickHouse: Examples from Support Services

Customer stories
Querying ClickHouse on your Phone with Zing Data & ChatGPT

Engineering
A Deep Dive into Apache Parquet with ClickHouse - Part 2

Customer stories
How AdGreetz Processes Millions of Daily Ad Impressions with ClickHouse Cloud
Product
ClickHouse Newsletter April 2023: Lightweight Deletes

Customer stories
Serving Real-Time Analytics Across Marketplaces at Adevinta with ClickHouse Cloud
Customer stories
A ClickHouse-powered Observability Solution: Overview of Highlight.io

Engineering
ClickHouse Joins Under the Hood - Hash Join, Parallel Hash Join, Grace Hash Join

Engineering
A Deep Dive into Apache Parquet with ClickHouse - Part 1
Customer stories
How we used ClickHouse to store OpenTelemetry Traces and up our Observability Game

Engineering
ClickHouse Release 23.3

Company and culture
My Journey as a Serial Startup Product Manager
Engineering
Speeding up LZ4 in ClickHouse

Engineering
Building Real-time Analytics Apps with ClickHouse and Hex

Engineering
Building an Observability Solution with ClickHouse - Part 2 - Traces

Company and culture
Women Who Inspire Us: The Women Building ClickHouse

Company and culture
ClickHouse, Inc. and Alibaba Cloud Announce a New Partnership

Engineering
Optimizing Analytical Workloads: Comparing Redshift vs ClickHouse
Product
ClickHouse Newsletter March 2023: Contributing to ClickHouse

Product
Building ClickHouse Cloud From Scratch in a Year

Company and culture
Women Who Inspire Us: Balancing Family, Career Changes and Startup Life - Elissa’s Journey in Tech
Engineering
Handling Updates and Deletes in ClickHouse
Customer stories
Fintech Leader Juspay Analyzes Over 50 Million Daily Payment Transactions in Real-Time with ClickHouse

Engineering
ClickHouse Release 23.2

Company and culture
Women Who Inspire Us: The Women Pioneers in ClickHouse Community and Company

Engineering
Join Types supported in ClickHouse

Engineering
ClickHouse vs BigQuery: Using ClickHouse to Serve Real-Time Queries on Top of BigQuery Data

Engineering
Five Methods For Database Obfuscation

Engineering
ClickHouse welcomes Metabase Cloud GA integration

Product
ClickHouse Newsletter February 2023: A ‘Sample’ of What’s Happening in the Community

Engineering
A Story of Open-source GitHub Activity using ClickHouse + Grafana
Engineering
Introducing the ClickHouse Query Cache

Engineering
Using Aggregate Combinators in ClickHouse

Engineering
Analyzing AWS Flow Logs using ClickHouse

Company and culture
For the Love of Coffee (and Distributed Working)
Engineering
Introducing Inverted Indices in ClickHouse

Engineering
ClickHouse and dbt - A Gift from the Community
Engineering
Using TTL to Manage Data Lifecycles in ClickHouse

Engineering
ClickHouse Release 23.1

Customer stories
Trillabit Utilizes the Power of ClickHouse for Fast, Scalable Results Within Their Self-Service, Search-Driven Analytics Offering

Engineering
ClickHouse and PostgreSQL - a Match Made in Data Heaven - part 2
Engineering
An Introduction to Data Formats in ClickHouse
Customer stories
ClickHouse Powers Dassana’s Security Data Lake
Engineering
ClickHouse Fiddle — A SQL Playground for ClickHouse
Engineering
Using Materialized Views in ClickHouse

Product
ClickHouse Newsletter January 2023: Better Safe Than Sorry
Community
Seattle Meetup Report: Petabyte-Scale Website Behavior Analytics using ClickHouse (Microsoft)
Community
Seattle Meetup Report: Self-Service Data Analytics for Microsoft’s Biggest Web Properties with ClickHouse

Engineering
Sending Windows Event Logs to ClickHouse with Fluent Bit

Engineering
Announcing a New Official ClickHouse Kafka Connector

Engineering
Building an Observability Solution with ClickHouse - Part 1 - Logs
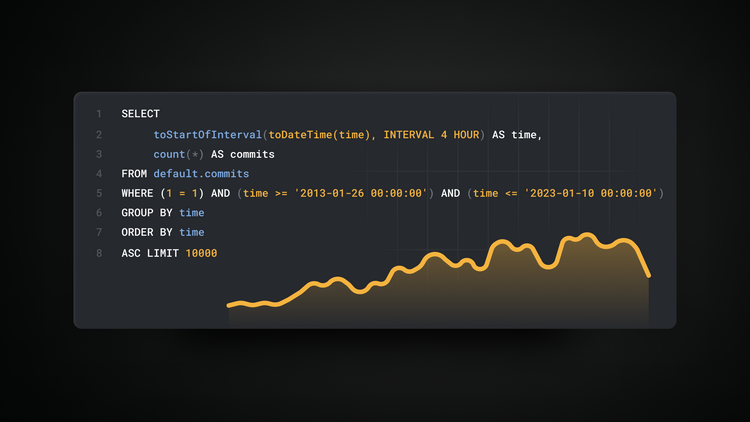
Engineering
Working with Time Series Data in ClickHouse
Customer stories
HIFI’s migration from BigQuery to ClickHouse

Engineering
Using ClickHouse to Monitor Job Queues in GitHub Actions
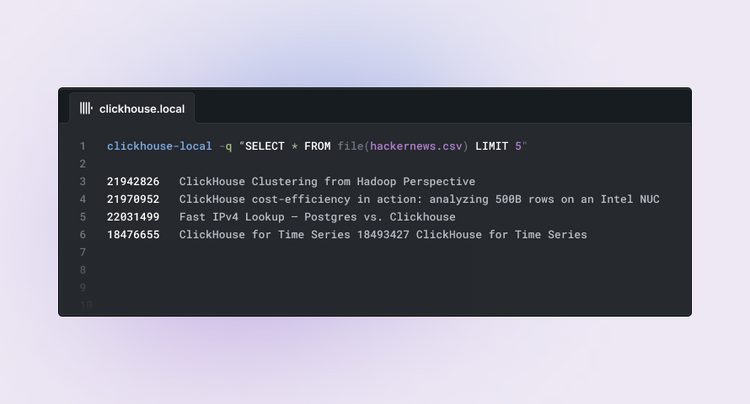
Engineering
Extracting, Converting, and Querying Data in Local Files using clickhouse-local

Engineering
Essential Monitoring Queries - part 2 - SELECT Queries
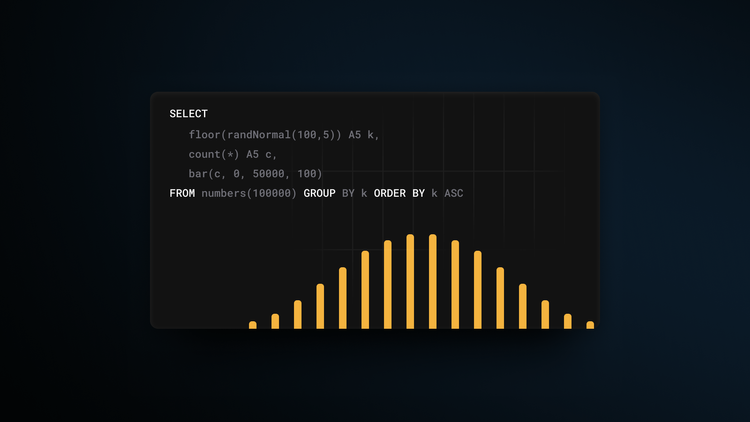
Engineering
Generating Random Data in ClickHouse

Engineering
Essential Monitoring Queries - part 1 - INSERT Queries

Product
System Tables and a Window into the Internals of ClickHouse
Engineering
ClickHouse and PostgreSQL - a Match Made in Data Heaven - part 1

Engineering
ClickHouse Release 22.12

Engineering
Super charging your ClickHouse queries

Engineering
Optimizing ClickHouse with Schemas and Codecs

Product
ClickHouse Newsletter December 2022: Project all your troubles away

Engineering
User-defined functions in ClickHouse Cloud

Engineering
Using Dictionaries to Accelerate Queries
Community
NYC Meetup Report: Large Scale Financial Market Analytics with ClickHouse (Bloomberg)
Community
NYC Meetup Report: Real-time Slicing and Dicing Reporting with ClickHouse (Rokt)

Product
ClickHouse Cloud is now Generally Available

Company and culture
ClickHouse Launches Cloud Offering For World’s Fastest OLAP Database Management System

Engineering
ClickHouse 22.11 Release

Product
ClickHouse Cloud is now SOC 2 Type II Compliant

Engineering
JIT in ClickHouse

Engineering
Window and array functions for Git commit sequences

Engineering
Git commits and our community

Product
ClickHouse Newsletter November 2022: The purifying effects of obfuscation
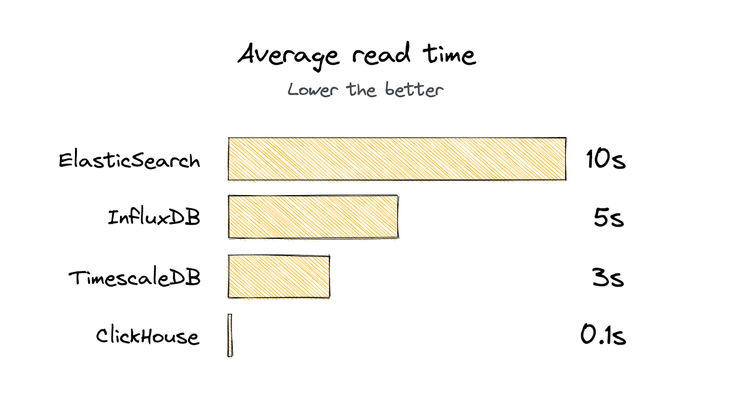
Customer stories
100x Faster: GraphQL Hive migration from Elasticsearch to ClickHouse

Company and culture
ClickHouse Spotlight: Niek Lok

Engineering
Sending Kubernetes logs To ClickHouse with Fluent Bit

Engineering
Getting started with ClickHouse? Here are 13 "Deadly Sins" and how to avoid them
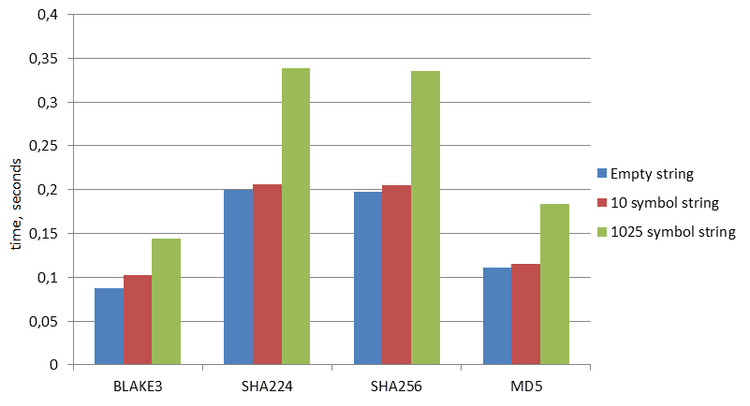
Engineering
More Than 2x Faster Hashing in ClickHouse Using Rust

Engineering
Sending Nginx logs to ClickHouse with Fluent Bit

Engineering
Node.js client for ClickHouse
Engineering
Visualizing Data with ClickHouse - Part 3 - Metabase

Engineering
The world’s fastest tool for querying JSON files

Product
ClickHouse Newsletter October 2022: A cloud has arrived

Engineering
Visualizing Data with ClickHouse - Part 2 - Superset
Customer stories
Contentsquare Migration from Elasticsearch to ClickHouse
Engineering
Visualizing Data with ClickHouse - Part 1 - Grafana

Product
ClickHouse Cloud is now in Public Beta

Engineering
Getting Data Into ClickHouse - Part 3 - Using S3

Product
ClickHouse Newsletter September 2022: Deleting data can make you feel better

Company and culture
ClickHouse Spotlight: San Tran

Engineering
Exploring massive, real-world data sets: 100+ Years of Weather Records in ClickHouse

Engineering
ClickHouse Plugin for Grafana - 2.0 Release

Engineering
Getting Data Into ClickHouse - Part 2 - A JSON detour

Engineering
Getting Data Into ClickHouse - Part 1

Product
ClickHouse Newsletter August 2022: Airlines are maybe not that bad

Customer stories
From experimentation to production, the journey to Supercolumn
Customer stories
Fast, Feature Rich and Mutable : ClickHouse Powers Darwinium's Security and Fraud Analytics Use Cases
Customer stories
DeepL’s journey with ClickHouse

Company and culture
ClickHouse Spotlight: Claire Lucas

Product
ClickHouse Newsletter July 2022: Geo queries for railway enthusiasts

Customer stories
ClickHouse + Deepnote: Data Notebooks & Collaborative Analytics
Customer stories
Optimizing your customer-facing analytics experience with Luzmo and ClickHouse
Customer stories
Collecting Semi-structured Data from Kafka Topics Using ClickHouse Kafka Engine
Engineering
ClickHouse Over the Years with Benchmarks
Product
ClickHouse Newsletter June 2022: Materialized, but still real-time

Company and culture
Amsterdam Meetup With The ClickHouse Team – June 8th, 2022
Customer stories
How QuickCheck uses ClickHouse to bring banking to the Unbanked
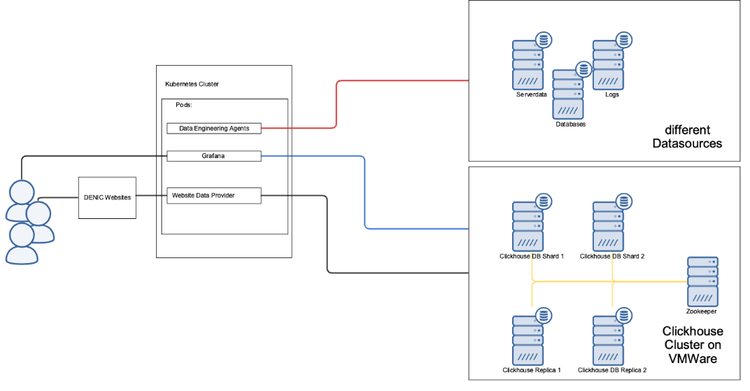
Customer stories
DENIC Improves Query Times By 10x with ClickHouse

Product
ClickHouse Newsletter May 2022: Explain Statement – Query Optimization
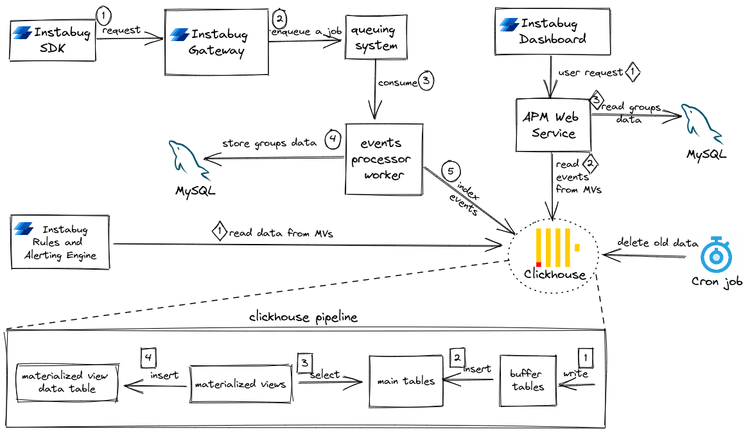
Customer stories
10x improved response times, cheaper to operate, and 30% storage reduction: why Instabug chose ClickHouse for APM

Company and culture
ClickHouse Docs have a new look and feel!

Product
ClickHouse Newsletter April 2022: JSON, JSON, JSON

Engineering
ClickHouse 22.3 LTS Released

Engineering
Building a Paste Service With ClickHouse

Company and culture
We Stand With Ukraine
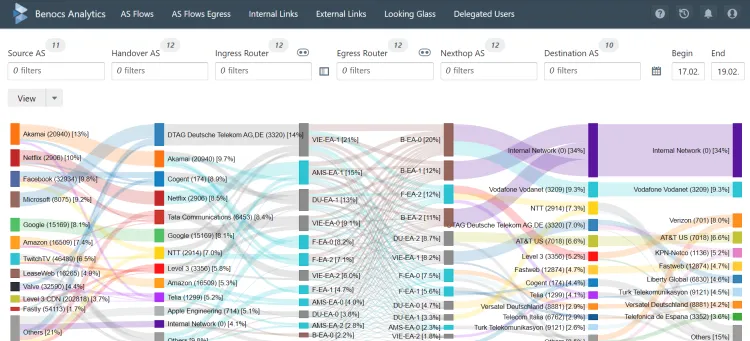
Customer stories
How BENOCS uses ClickHouse to monitor network traffic for the world’s biggest telcos

Company and culture
International Women’s Day 2022: #BreakTheBias

Company and culture
Stories of Difference, Inspiration, Courage, and Empathy: International Women’s Day 2022

Product
ClickHouse Newsletter March 2022: There’s a window function for that!

Product
ClickHouse 22.2 Released

Customer stories
Opensee: Analyzing Terabytes of Financial Data a Day With ClickHouse

Product
ClickHouse Newsletter February 2022: Do you know how to search a table?

Product
What’s New in ClickHouse 22.1
Customer stories
Admixer Aggregates Over 1 Billion Unique Users a Day using ClickHouse
Engineering
Decorating a Christmas Tree With the Help Of Flaky Tests

Product
What’s New in ClickHouse 21.12

Engineering
How to Enable Predictive Capabilities in ClickHouse Databases
Customer stories
Plausible Analytics uses ClickHouse to power their privacy-friendly Google Analytics alternative

Company and culture
ClickHouse Moscow Meetup October 19, 2021

Engineering
ClickHouse v21.11 Released

Company and culture
ClickHouse raises a $250M Series B at a $2B valuation...and we are hiring
Engineering
ClickHouse v21.10 Released

Company and culture
Introducing ClickHouse, Inc.

Engineering
Testing the Performance of ClickHouse

Engineering
The Tests Are Passing, Why Would I Read The Diff Again?
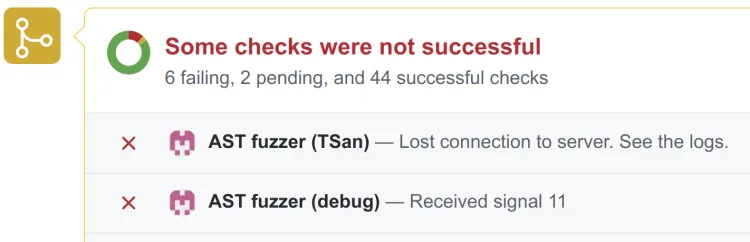
Engineering
Fuzzing ClickHouse
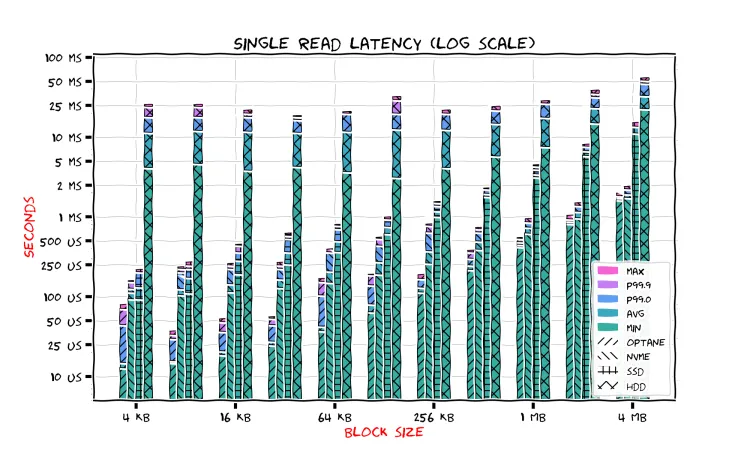
Engineering
A journey to io_uring, AIO and modern storage devices

Engineering
Running ClickHouse on an Android phone
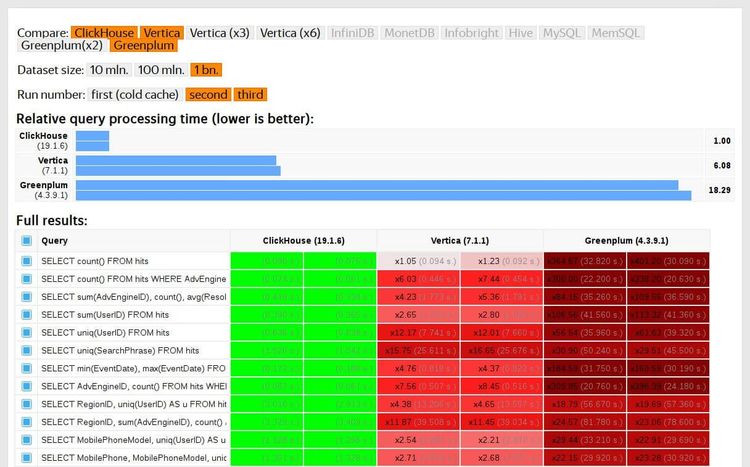
Engineering
Five Methods for Database Obfuscation
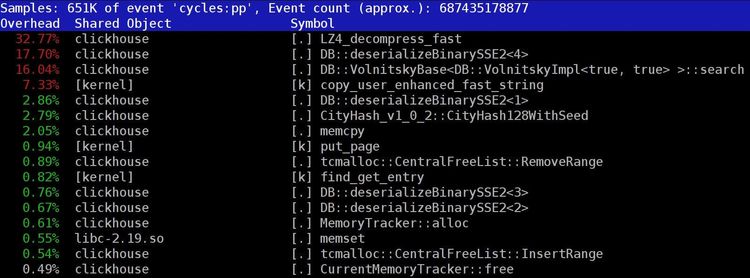
Engineering
How to speed up LZ4 decompression in ClickHouse?

Engineering
ClickHouse Lecture at Institute of Computing Technology, Chinese Academy of Science on June 11, 2019

Company and culture
ClickHouse Meetup in Beijing on June 8, 2019

Company and culture
ClickHouse at Percona Live 2019

Company and culture
ClickHouse Meetup in San Francisco on June 4, 2019

Company and culture
ClickHouse Meetup in Limassol on May 7, 2019

Company and culture
Schedule of ClickHouse Meetups in China for 2019

Company and culture
Concept: "Cloud" MergeTree Tables

Company and culture
ClickHouse at Percona Live Europe 2018
Company and culture
ClickHouse Meetup in Amsterdam on November 15, 2018

Company and culture
ClickHouse Community Meetup in Beijing on October 28, 2018

Company and culture
ClickHouse at Analysys A10 2018

Company and culture
Announcing ClickHouse Meetup in Amsterdam on November 15

Company and culture
ClickHouse Community Meetup in Paris on October 2, 2018

Company and culture
ClickHouse Community Meetup in Berlin on July 3, 2018

Company and culture
Announcing ClickHouse Community Meetup in Berlin on July 3

Company and culture
ClickHouse Meetup in Madrid on April 2, 2019
Company and culture
ClickHouse Community Meetup in Beijing on January 27, 2018

Company and culture
Join the ClickHouse Meetup in Berlin

Company and culture
ClickHouse Meetup in Berlin, October 5, 2017

Company and culture
ClickHouse at Data@Scale 2017

Company and culture
ClickHouse Meetup in Santa Clara on May 4, 2017

Company and culture
ClickHouse at Percona Live 2017
Engineering
Evolution of Data Structures in Yandex.Metrica

Product
How to Update Data in ClickHouse
Company and culture
Yandex Opensources ClickHouse
Follow us
Comparisons
Stay informed on feature releases, product roadmap, support, and cloud offerings!
Loading form...
© 2024 ClickHouse, Inc. HQ in the Bay Area, CA and Amsterdam, NL.